CarbonData是由华为开源并支持Hadoop的列式存储文件格式,支持索引、压缩以及解编码等。其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询,目前该项目正处于Apache孵化阶段。本文在简单介绍CarbonData基础上,利用SSB基准测试工具对CarbonData与其他多种列式文件存储格式进行简单测试。部分内容来自@大月同学。
一、简介
1.1 背景
针对数据的需求分析主要有以下5点要求:
(1)支持海量数据扫描提取其中某些列;
(2)支持根据主键进行查找的低于秒级响应;
(3)支持海量数据进行交互式查询的秒级响应;
(4)支持快速地抽取单独记录,并且从该记录中获取到所有列信息;
(5)支持HDFS,可以与Hadoop集群进行很好的无缝兼容。
现有的Hadoop生态系统中没有同时满足这五点要求文件格式。比如Parquet/ORC的文件能够满足第一和第五条要求,其他的要求无法满足,基于这些事实华为开发了CarbonData。
1.2 优势
CarbonData文件格式是基于列式存储的,并存储在HDFS之上;其包含了现有列式存储文件格式的许多优点,比如:可分割、可压缩、支持复杂数据类型等。
CarbonData为了解决前面提到的几点要求,加入了许多独特的特性,主要概括为以下四点:
(1)数据及索引:在有过滤的查询中,它可以显著地加速查询性能,减少I/O和CPU资源;CarbonData的索引由多级索引组成,计算引擎可以利用这些索引信息来减少调度和一些处理的开销;扫描数据的时候可以仅仅扫描更细粒度的单元(称为blocklet),而不再是扫描整个文件;
(2)可操作的编码数据:通过支持高效的压缩和全局编码模式,它可以直接在压缩或者编码的数据上查询,仅仅在需要返回结果的时候才进行转换,更好的查询下推;
(3)列组:支持列组,并且使用行格式进行存储,减少查询时行重建的开销;
(4)多种使用场景:顺序存取、随机访问、类OLAP交互式查询等。
1.3 文件格式
一个CarbonData文件是由一系列被称为blocklet组成的,除了blocklet,还有许多其他的元信息,比如模式、偏移量以及索引信息等,这些元信息是存储在CarbonData文件中的footer里。
当在内存中建立索引的时候都需要读取footer里面的信息,因为可以利用这些信息优化后续所有的查询。
每个blocklet又是由许多Data Chunks组成。Data Chunks里面的数据可以按列或者行的形式存储;数据既可以是单独的一列也可以是多列。文件中所有blocklets都包含相同数量和类型的Data Chunks。CarbonData文件格式如图1所示。
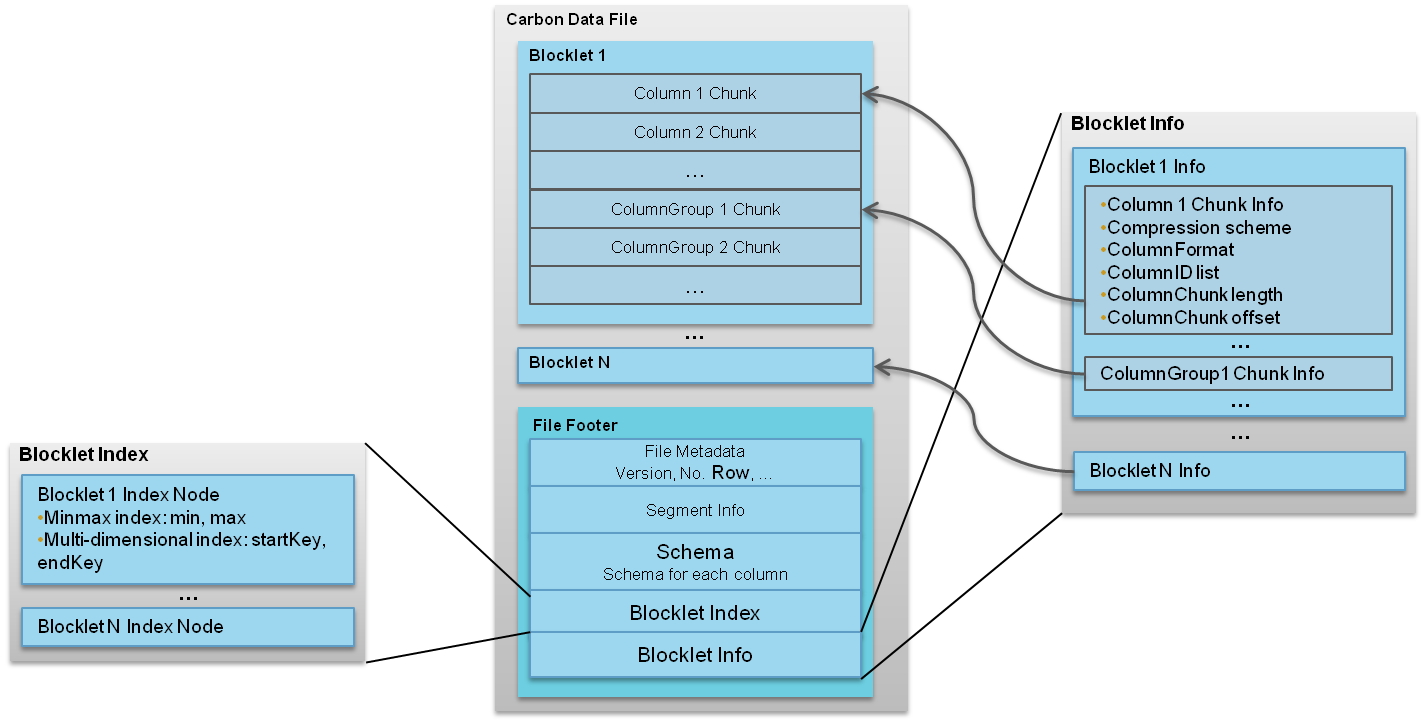
每个Data Chunk又是由许多被称为Pages的单元组成。总共有三种类型的pages:
(1)Data Page:包含一列或者列组的编码数据;
(2)Row ID Page:包含行id的映射,在Data Page以反向索引的形式存储时会被使用;
(3)RLE Page:包含一些额外的元信息,只有在Data Page使用RLE编码的时候会被使用。
二、SSB介绍
SSB全称Star Schema Benchmark,顾名思义,是一套用于测试数据库产品在星型模式下性能表现的基准测试规范,目前在学术界和工业界都得到了广泛的使用。提到数据仓库系统(更广义地说,决策支持系统)的基准测试规范,最权威的莫过于TPC-H和TPC-DS这两套规范,他们都由非营利组织TPC(事务处理性能理事会)发布。SSB实际上就是基于TPC-H修改而来的,将TPC-H的雪花模式简化为了星型模式,将基准查询由TPC-H的复杂Ad-Hoc查询改为了结构更固定的OLAP查询。
SSB的设定为零售业订单的产品、供应商分析场景,Schema包含一张事实表「订单lineorder」和四张维表:「消费者customer」, 「供应商supplier」, 「零件part」, 「日期date」,构成了一个典型的星型模式。图1中,表名下方的"SF * 30,000"代表各表的数据行数。例如,当SF=1时,事实表lineorder包含6,000,000行数据,维表customer包含30,000行数据,Date表的行数固定,不随SF变化。
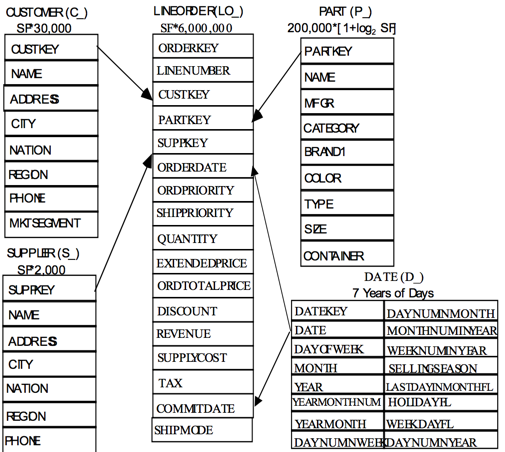
SSB的基准查询专注于星型模式下的一类典型查询:读取事实表一次,连接各个维表,对某些维度属性做过滤,最后对某些维度属性分组聚集。在此基础上,SSB重点关注以下方面:
(1)提升「功能覆盖率」:基准查询集合应当尽可能地覆盖对星型模式的各种查询类型。SSB的基准查询分为四组,分别测试带2、3、4个维度属性过滤的情况,基本覆盖了多数场景;
(2)提升「选择度覆盖率」:某个查询最终需要读取的事实表行数(即事实表的选择度)由各个维度过滤条件的FF(过滤因子)决定。基准查询应当覆盖不同的选择度。SSB的基准查询的选择度大到1.9%,小到百万分之1,覆盖了很宽的范围;
(3)减小缓存的影响:如果相邻的两个基准查询扫描的事实数据有很大的重合,后者很有可能直接从缓存中读取数据,这会影响最终的测试结果。因此应当尽量避免基准查询读取重合的事实数据。
SSB的完整规范见http://www.cs.umb.edu/~poneil/StarSchemaB.PDF%E3%80%82
简单说明:
SF(Scale Factor) :生成测试数据集时传入的数据量规模因子,决定了各表最终生成的行数。
FF(Filter Factor):每个where过滤条件筛选出一部分行,被筛选出的行数占过滤前行数的比例叫做FF。在过滤列彼此独立的条件下,表的FF为该表上各个过滤条件FF的乘积。
三、安装使用
SSB的安装是指测试数据集生成工具dbgen的安装,步骤如下:
(1)下载代码。官方提供的代码不支持在Mac上编译,这里我们使用Presto开发人员修改过的版本;
1 2 | |
(2)如果在Mac上编译,直接运行make即可。如果在Linux上编译,需要修改makefile,将“MACHINE =MAC”改为“MACHINE =LINUX”;
(3)编译后的可执行程序为dbgen,它依赖一个数据分布文件dists.dss。dbgen默认将测试数据生成在当前目录,如果需要生成到其他目录,可以将dbgen和dists.dss拷贝到对应目录使用;
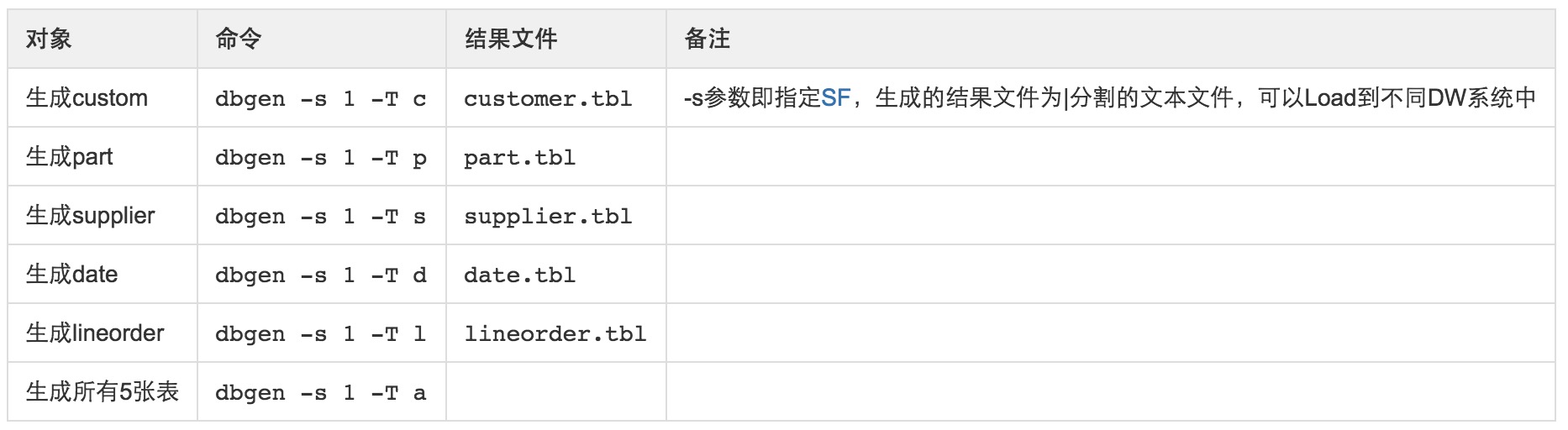
(4)使用dbgen生成测试数据。
四、基准测试用例
SSB提供了一套标准对各个数据仓库/OLAP系统进行性能测试和比较,其最大的特点:使用星型模式、基准查询代表性强、可以生成任意量级的测试数据。SSB的基准查询集分为4组,共13个查询。每组的查询结构类似,但「选择度」不同。这里列出每个查询的SQL和FF以及需要的事实表行数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 | |
五、测试过程
5.1 测试范围
为了尽可能覆盖多种列式存储系统的性能表现,本次测试选择了ORC,Parquet和CarbonData。
5.2 测试数据规模
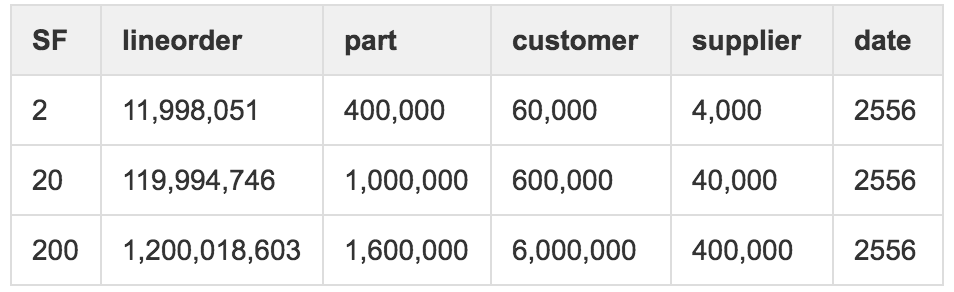
我们希望测到千万级、亿级和十亿级事实表的规模,因此分别选择了2、20、200的SF(Scale Factor),对应的各表行数如下:
5.3 测试数据准备
由于CarbonData的数据导入必须依赖csv文件,但是dbgen生成的是"|“分割的文本数据,所以利用dbgen生成数据后需要先对测试数据进行一次预处理,将其转换成各系统均可识别的格式。最后,为避免测试过程中,数据缓存对测试结果的影响,为不同的存储系统和SF建立不同的测试表{table}_{format}_{scale},如lineorder_orc_2。
综上考虑,以SF=2为例,数据准备分为三步:
(1)使用dbgen生成文本的测试数据;
(2)预处理生成的测试数据将其转换成csv格式;
(3)将csv格式的测试数据按照{table}_{format}_{scale}导入不同存储格式的表中;
最终在测试库下会生成包括文本存储格式数据在内共60张测试表{table}_{format}_{scale};
测试数据在HDFS上副本因子统一为3;
附:建表语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 | |
5.4 测试方法
使用13个基准查询对各系统进行测试,测试期间尽量避免队列资源存在竞争情况。每个基准查询跑三遍,结果取均值。
为减少不同计算引擎之间的差异,本次测试基于Spark 1.5.2进行,详细配置如下:
1
| |
对于CarbonData选择相同的资源选项。
1
| |
附Hadoop集群环境:
(1)JDK:1.7.0_76 HotSpot™ 64-Bit Server
(2)Hadoop:2.7.1
(3)Spark:1.5.2
(4)HDFS Replica Ratio:3
5.5 测试结果
1、数据导入时间对比
数据导入时间可参考:Apache CarbonData Performance Benchmark,数据导入效率表现基本一致,orc与parquet无明显差别,这里不再详述。
2、存储资源占用对比
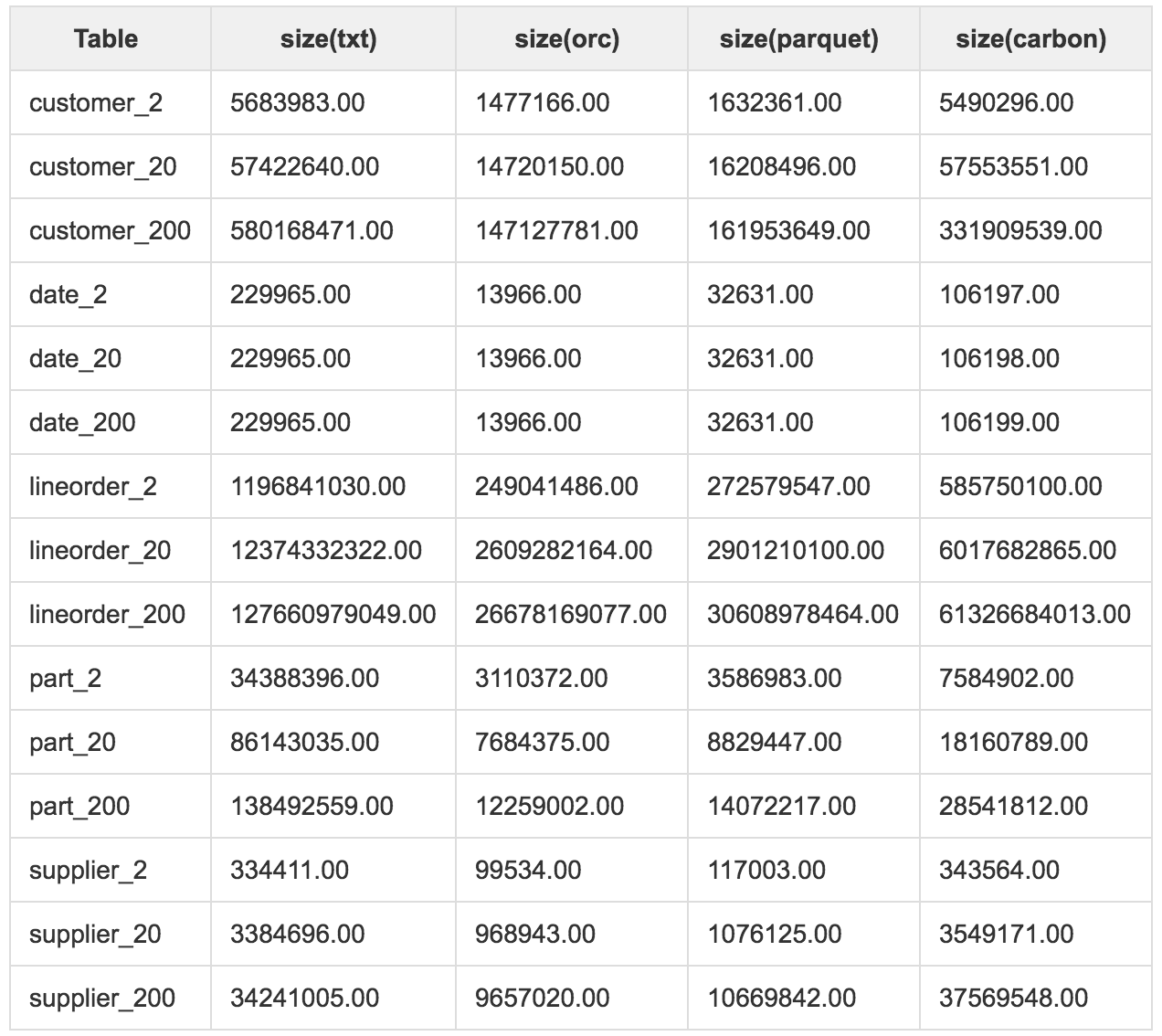
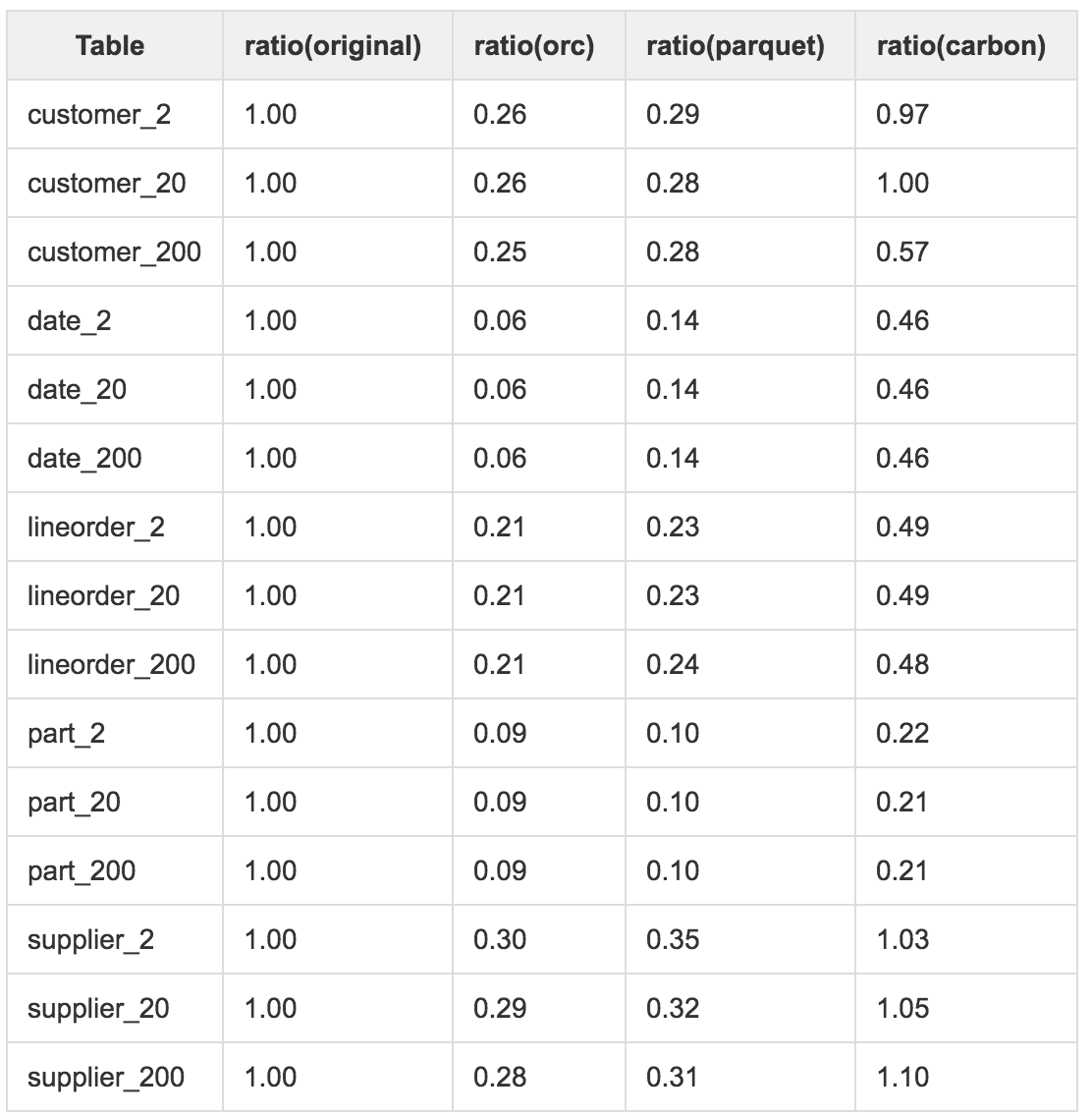
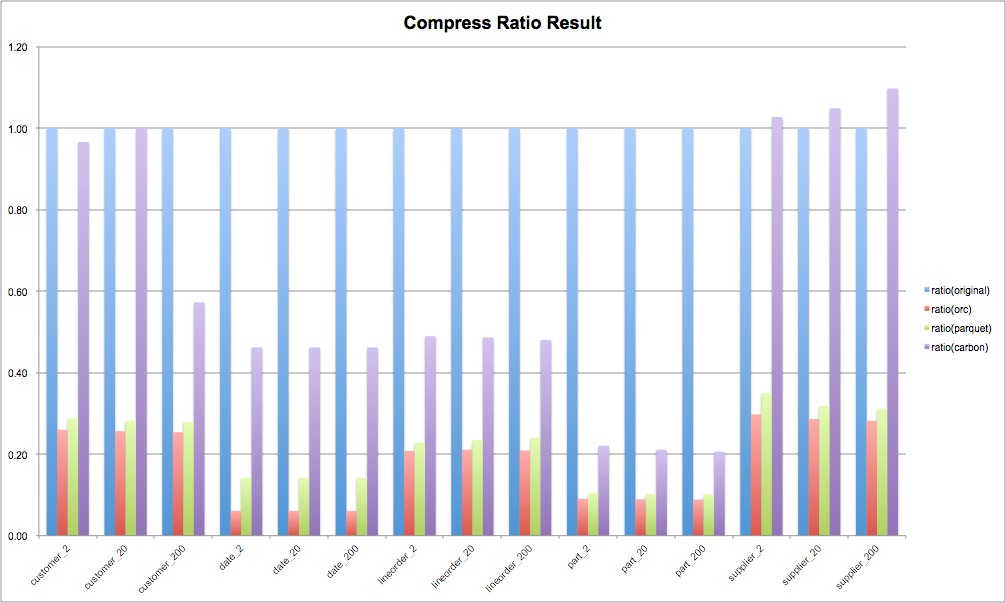
从数据压缩率的测试结果可以看出:
(1)orc和parquet的数据压缩率与数据本身的关系并不大,基本可以控制在0.3以内,但是CarbonData对数据的压缩能力并不好,对于SSB的测试数据集,压缩率主要集中在0.4上下;
(2)需要关注的的是CarbonData中部分数据甚至超过的原始文本数据大小;
3、查询效率对比
注:下面关于查询效率的测试数据中包含了作业提交时间、JVM启动时间等,数据本身存在少许误差。
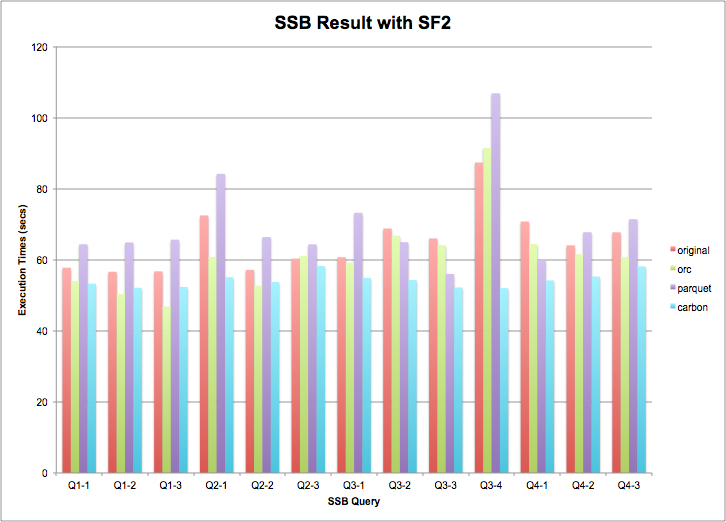
从SF=2数据规模下查询效率对比数据来看:
(1)多种存储系统的查询性能差别并不大;
(2) 整体来看,CarbonData稍微优于其他存储系统;
如果考虑到作业提交时间及JVM启动时间的误差,在SF2数据规模下的结果基本没有明显差异;
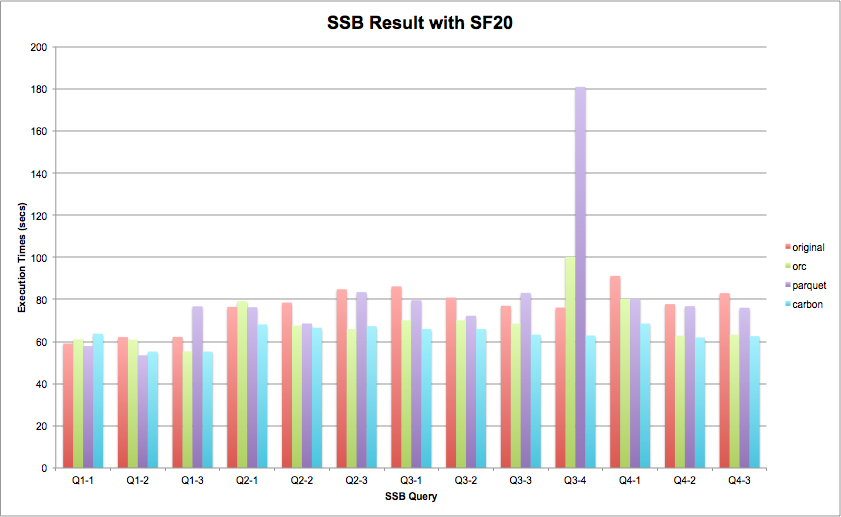
注:在SF=20数据规模下的测试结果看,结论与SF=2保持一致;
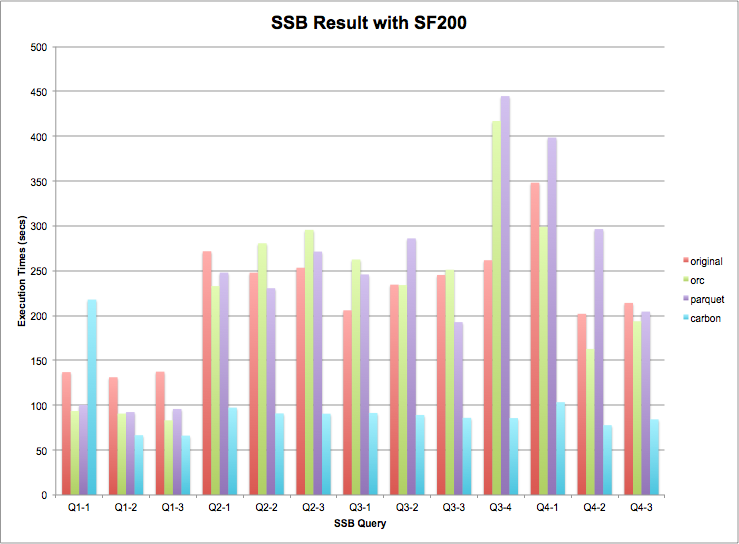
在SF=200的数据规模查询效率对比数据来看:
(1)所有查询模式中,carbon明显优于其他存储系统;
(2)从整体上看,ORC/Parquet没有明显区别,基本可认为性能表现相似;
如果考虑到作业提交时间及JVM启动时间的误差,作业执行时间的差异表现差异非常明显,CarbonData具有非常好的优势;
六、结论
1、从查询性能上看,CarbonData具备非常好的优势,主要原因:
(1)MDK,Min-Max and Inverted Index等辅助信息可对结果数据进行更快速的查询,也能高效重建结果数据;
(2)列组(Column group)技术消除了行数据重建时隐式Join操作;
(3)使用全局字典编码加快计算速度,处理/查询引擎直接在编码数据上进行处理而不需要转换;
(4)延迟解码使得聚合操作更快,只有需要返回结果给用户时才进行解码转换。
2、由于CarbonData在加载数据时需要建立索引和全局字典编码,所以在数据加载和压缩率上比ORC和Parquet都要差,尤其在对一些特殊结构的数据表现较差,更适合一次写多次读且对存储资源使用不敏感的场景。
3、截止2016.10.01最新发布版本carbondata-0.1.0,在功能完备性、系统稳定性等方面还有提升空间,社区也在持续改进完善。
4、从整体上看,CarbonData优异的查询性能表现及社区的持续改进优化,未来非常值得期待。
七、参考
[1] https://github.com/apache/incubator-carbondata
[2] https://cwiki.apache.org/confluence/display/CARBONDATA/CarbonData+Home
[3] https://www.iteblog.com/archives/1806