Apache Kylin是基于Hadoop之上的SQL多维分析引擎,具有支持海量数据、秒级响应、高并发等特点。Kylin中使用的精确去重计数和全局字典技术在相关领域里非常具有借鉴意义。本文作者来自Apache Kylin社区PMC成员@Sunyerui,谢绝转载。
一、问题背景
在OLAP数据分析中,去重计数(count distinct)是非常常见的需求,且通常希望统计的结果是精确值,也就是说需要精确去重计数。
但在超大的数据集规模上,实现精确去重计数是一件非常困难的事,一句话总结:超大规模数据集下精确去重与快速响应之间的矛盾:
(1)超大规模数据集:意味着需要处理的数据量很多;
(2)精确去重:意味着要保留所有数据细节,这样才能使结果可上卷;
(3)快速响应:需要通过预计算或者内存计算等手段,加快速度;
上述条件相互约束,很难处理。因此目前主流OLAP系统都是采用近似去重计数的方式。
二、现状分析
在Apache Kylin中,目前提供的也是近似去重计数,是基于HLL(HyperLogLog)实现的。
简单来说,每个需要被计数的值都会经过特定Hash函数的计算,将得到的哈希值放入到byte数组中,最后根据特定算法对byte数据的内容进行统计,就可以得到近似的去重结果。
这种方式的好处是,不论数据有多少,byte数组的大小是有理论上限的,通常不会超过128KB,存储压力非常小。也就是说能够满足超大数据集和快速响应的要求。
但最大的问题就是结果是非精确的,这是因为保存的都是经过hash计算的值,而一旦使用hash就一定会有冲突,这就是导致结果不精确的直接原因。此外在实践中发现,hash函数的计算是计算密集型的任务,需要大量的CPU资源。
目前Apache Kylin提供的近似去重计数最高精度误差为1.44%,这在很多场景下是不能满足需求的,这促使我们考虑是否能在现有框架下实现精确去重计数的功能。
三、具体实现
3.1 Int型数据精确去重计数
回顾文初提到三个问题,为了保证去重结果是精确,统计的结果必须要保留细节,而信息保存的最小单位是bit,也就是说在最理想情况下,每个用于统计的值都在结果中用一个bit来保存。这样的分析使我们很容易想到bitmap这种数据结构,它可以以bit为单位保存信息,且可以根据数据分布进行有效压缩,节省最后的存储量。但bitmap通常只能实现对int类型(包括byte和short类型)的处理,所以我们可以先尝试只针对Int型数据实现精确去重计数。
目前业界有很多成熟的bitmap库可用,比如RoaringBitmap,ConciseSet等,其中RoaringBitmap的读写速度最快,存储效率也很高,目前已经在Spark,Drill等开源项目中使用,因此我们也选择了RoaringBitmap。经过试验,证明了我们的想法是可行的,通过实现一种新的基于bitmap的去重计算指标,确实能够实现对Int型数据的精确去重计数。在百万量级的数据量下,存储的结果可以控制在几兆,同时查询能够在秒级内完成,且可以支持任意粒度的上卷聚合计算。
3.2 Trie树与AppendTrie树
上述的结果能够满足Int类型数据的需求,但更多的数据是其它类型的,比如String类型的uuid。那么是否能够采用类似方式支持其它类型的精确去重计数呢?答案是肯定的。只要能将所有数据都统一映射到int类型的数据,那么就可以同样采用bitmap的方式解决问题。这样的映射关系有很多种实现方式,比如基于格式的编码,hash编码等,其中空间和性能效率都比较高,且通用性更强的是基于Trie树的字典编码方式。目前Apache Kylin之前已经实现了TrieDictionary,用于维度值的编码。
Trie树又名前缀树,是是一种有序树,一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,根节点对应空字符串,而每个字符串对应的编码值由对应节点在树中的位置来决定。图1是一棵典型的Trie树示意图,注意并不是每个节点都有对应的字符串值。
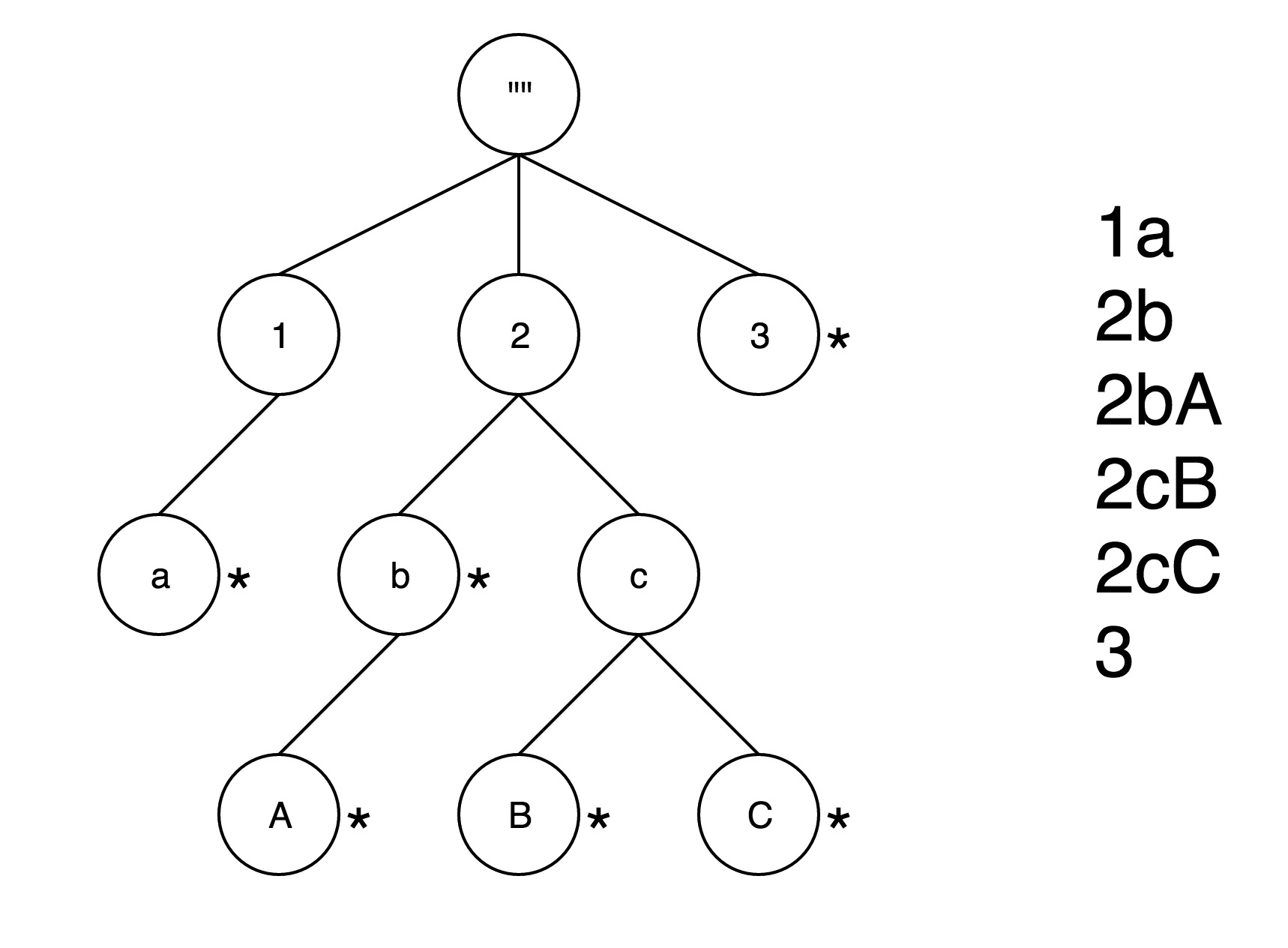
在构造Trie树时,将每个值依次加入到树中,可以分为三种情况,如图2所示。
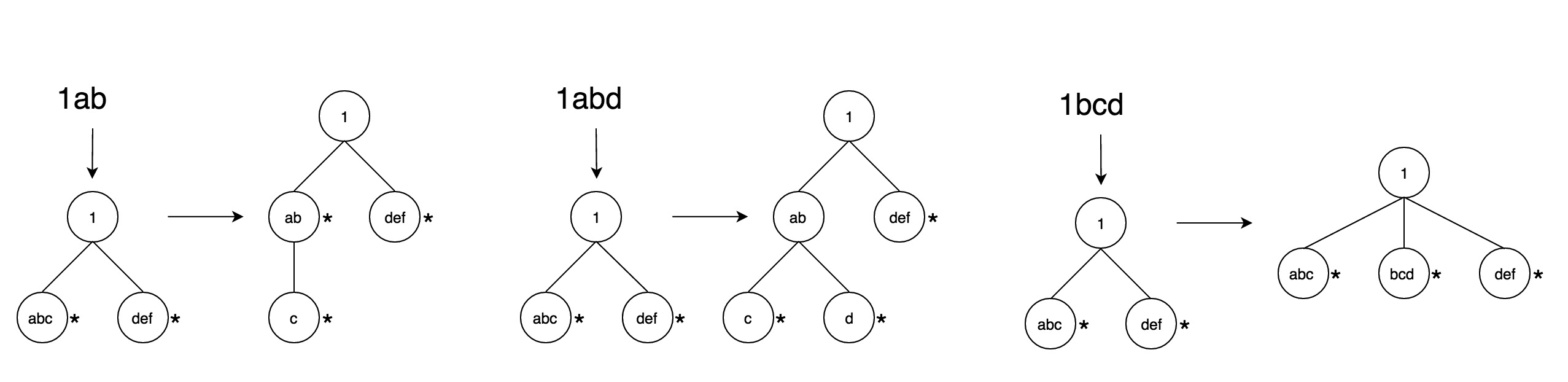
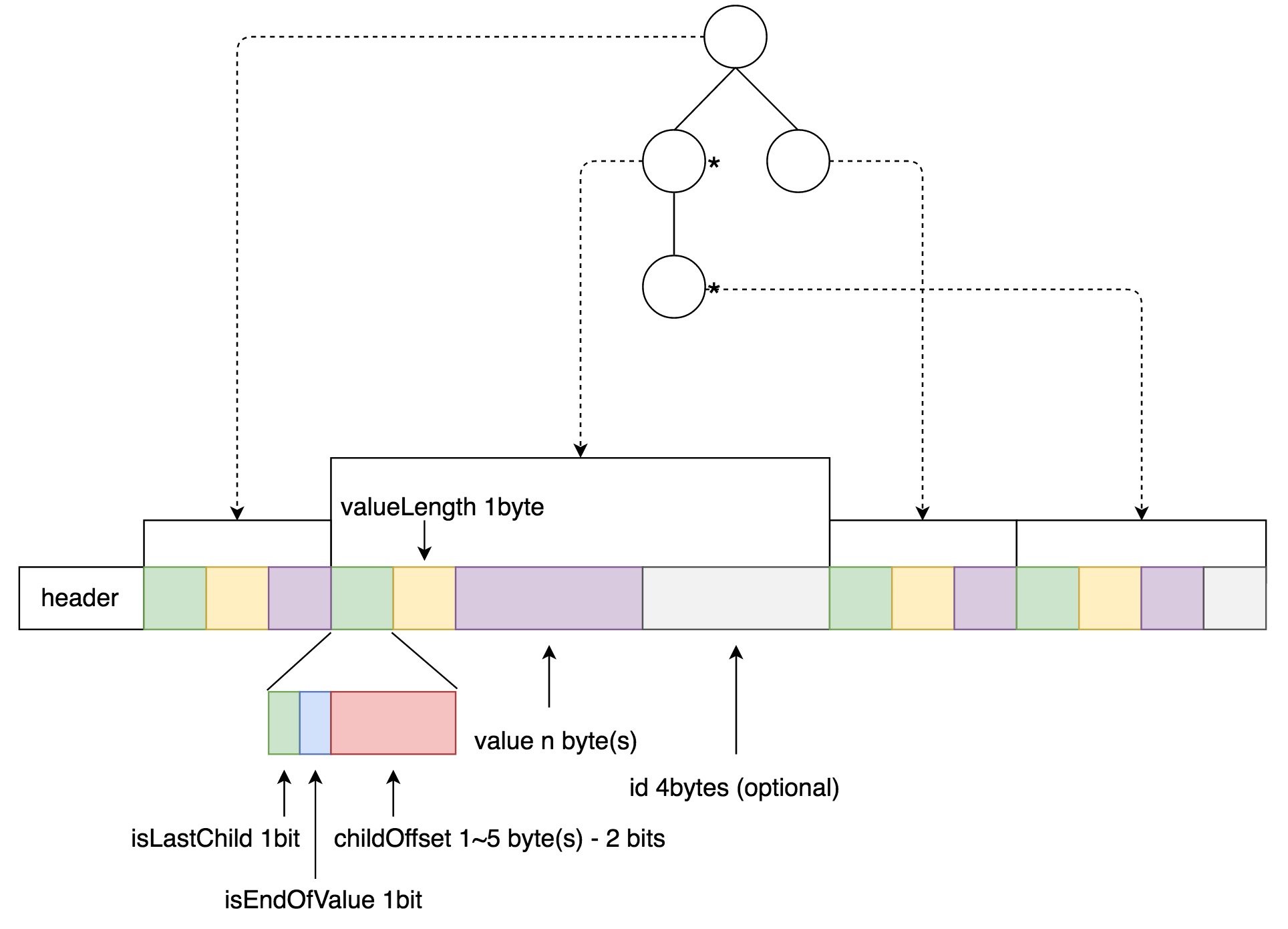
上述的是Trie树在构建过程中的内存模型,当所有数据加入之后,需要将整棵Trie树的数据序列化并持久化。具体的格式如图3所示。
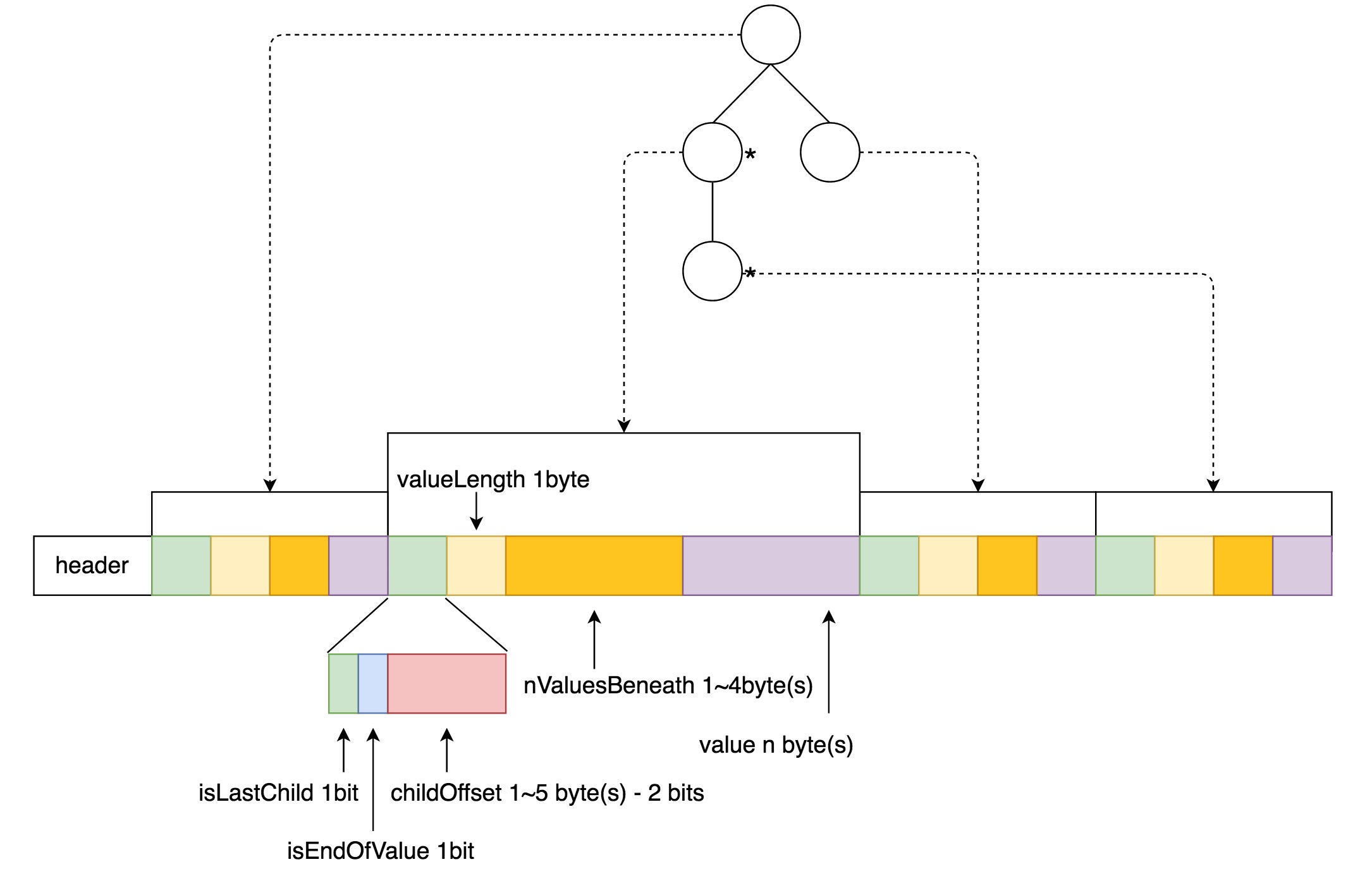
从图3中可以按照,整棵树按照广度优先的顺序依次序列化,其中childOffset和nValuesBeneath的长度是可变的,这是为了根据整棵树的大小尽可能使用更短的数据,降低存储量。此外需要注意到,childOffset的最高两位是标志位,分别标识当前节点是否是最后一个child,以及当前节点是否对应了原始数据的一个值。
当需要从字典中检索某个值的映射id时,直接从序列化后的数据读取即可,不需要反序列化整棵Trie树,这样能在保证检索速度的同时保持较低的内存用量。整个过程如图4所示。
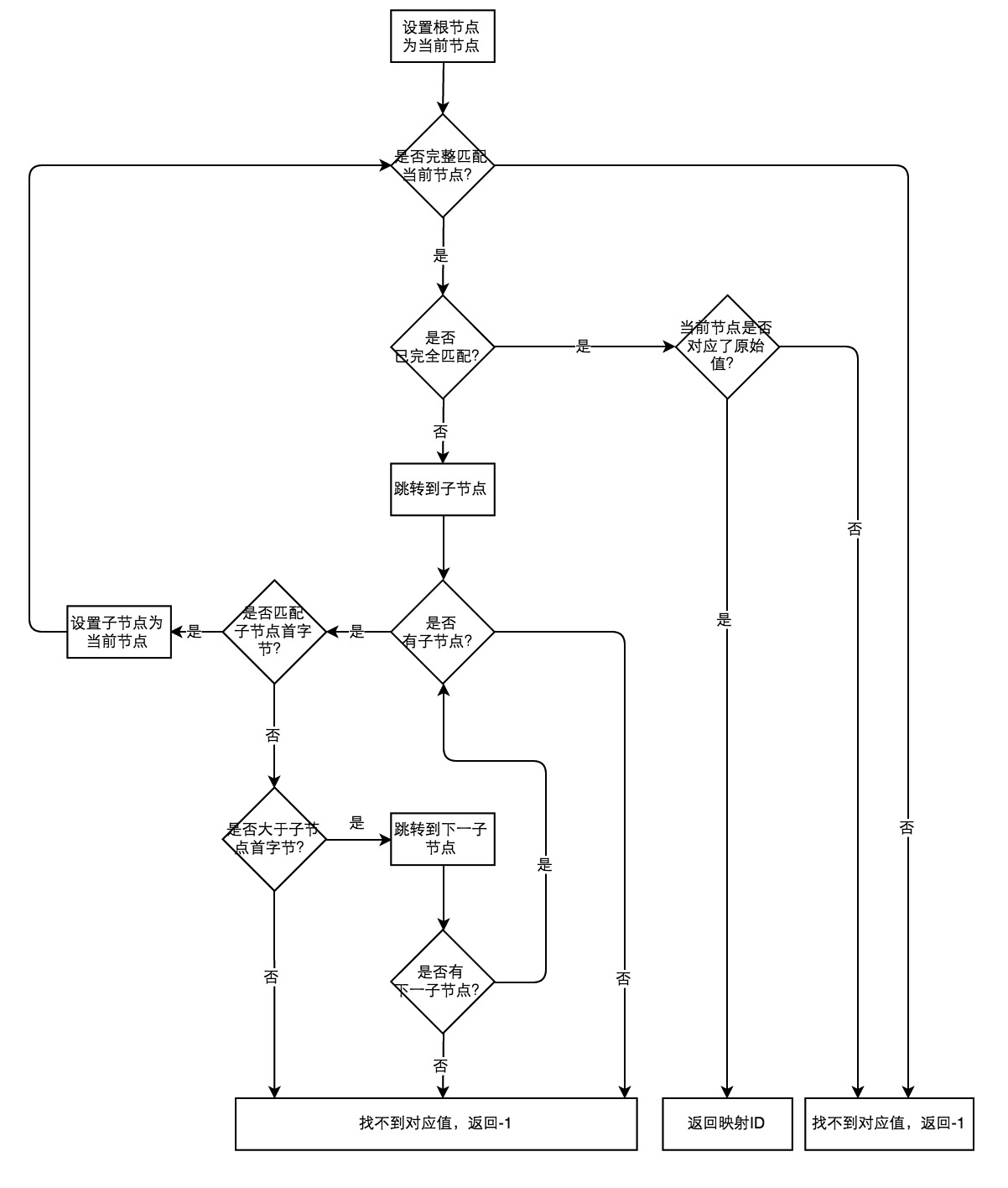
通过上述对Trie树的分析可以看到,Trie树的效率很高,但有一个问题,Trie树的内容是不可变的。也就是说,当一颗Trie树构建完成后,不能再追加新的数据进去,也不能删除现有数据,这是因为每个原始数据对应的映射id是由对应节点在树中的位置决定的,一旦树的结构发生变化,那么会导致部分原始数据的映射id发生变化,从而导致错误的结果。为此,我们需要对Trie树进行改造,使之能够持续追加数据,也就是AppendTrie树。
图5是AppendTrie的序列化格式,可以看到和传统Trie树相比,主要区别在于不保留每个节点的子value数,转而将节点对应的映射id保存到序列化数据中,这样虽然增大了存储空间,但使得整棵树是可以追加的。
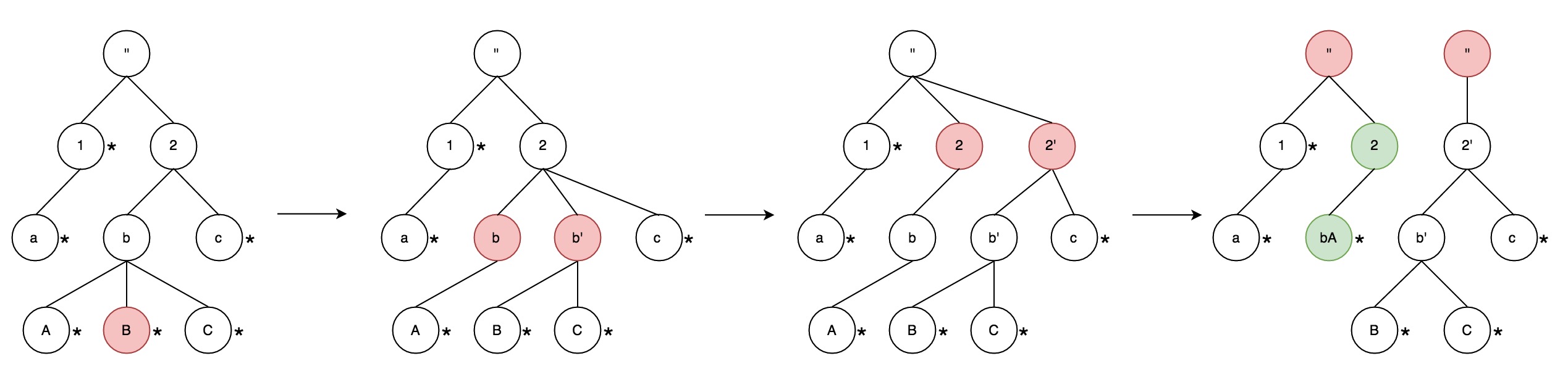
经过改造,AppendTrie树已经满足了我们的需求,能够支持我们实现对所有数据的统一编码,进而支持精确去重计数。但从实际情况来看,当统计的数据量超过千万时,整颗树的内存占用和序列化数据都会变得很大,因此需要考虑分片,将整颗树拆成多颗子树,通过控制每颗子树的大小,来实现整棵树的容量扩展。为了实现这个目标,当一棵树的大小超过设定阈值后,需要通过分裂算法将一棵树分裂成两棵子树,图6展示了整个过程。
在一棵AppendTrie树是由多棵子树构成的基础上,我们很容易想到通过LRU之类的算法来控制所有子树的加载和淘汰行为。为此我们基于guava的LoadingCache实现了特定的数据结构CachedTreeMap。这种map继承于TreeMap,同时value通过LoadingCache管理,可以根据策略加载或换出,从而在保证功能的前提下降低了整体的内存占用。
此外,为了支持字典数据的读写并发,数据持久化采用mvcc的理念,每次构建持久化的结果作为一个版本,版本一旦生成就不可再更改,后续更新必须复制版本数据后进行,并持久化为更新的版本。每次读取时则选择当前最新的版本读取,这样就避免了读写冲突。同时设置了基于版本个数和存活时间的版本淘汰机制,保证不会占用过多存储。
经过上述的改进和优化后,AppendTrie树完全达到了我们的要求,可以对所有类型的数据统一做映射编码,支持的数据量可以到几十亿甚至更多,且保持内存占用量的可控,这就是我们的可追加通用字典AppendTrieDictionary。
3.3 全局字典与全类型精确去重计数
基于AppendTrieDictionary,我们可以将任意类型的数据放到一个字典里进行统一映射。在Apache Kylin的现有实现中,Cube的每个Segment都会创建独立的字典,这种方式会导致相同数据在不同Segment字典中被映射成不同的值,这会导致最终的去重结果出错。为此,我们需要在所有Segment中使用同一个字典实例,也就是全局字典GlobaDictionary。
具体来说,根据字典的资源路径(元数据名+库名+表名+列名)可以从元数据中获取同一个字典实例,后续的数据追加也是基于这个唯一的字典实例创建的builder进行的。
另外,经常出现一个cube中需要对多列计算精确去重,这些列的数据基于同一数据源,且所有列是其中某列数据的子集,比如uuid类型的数据,此时可以针对包含全集数据的列建一份全局字典,其它列复用这一个字典即可。
图7展示了整个字典构建到应用的全过程。
四、结论与展望
通过对Bitmap和Trie树的合理运用和针对性优化,以及cache置换策略的应用,我们在Apache Kylin中成功实现了亿级规模的精确去重计数功能,支持任意粒度的上卷聚合,且保证内存可控。这里并没有全新的技术,只是对现有相关技术的组合运用,但解决了业界顶尖的技术难题。这也启发我们除了需要关注新技术,更应该多思考如何挖掘现有技术的潜力。
当然,目前的全局字典还存在一些问题和可改进的点,也欢迎更多讨论和贡献,其中包括:
(1)目前在内存有限,且字典较大时,容易出现字典分片被频繁换入换成的抖动,导致整体效率不高;
(2)全局字典只支持进程内的并发构建,但还不支持跨机器的并发构建;
(3)实际场景中,很多列的数据有高度相似性或属于同一来源,有可能共享同一个全局字典;