一、背景
集群在运行过程中,由于升级等原因难免会遇到重启NameNode或整个集群节点的情况,不同的重启方式会影响到整个运维操作的效率。
刚接触HDFS时的某次全集群内DataNode升级,遇到一次非预期内的NameNode重启。升级时,NameNode首先进入Safemode模式,全集群禁止写操作。DataNode数据包和配置更新后操作了所有DataNode一次性重启,之后NameNode间歇性不能响应,持续高负载达~45min,之后不得不通过重启NameNode,之后~35min全集群启动完成,服务恢复正常。
由此引出问题:
1、造成全集群DataNode重启后NameNode不能正常响应的根本原因是什么?
2、重启NameNode为什么能够实现恢复服务?
二、原因分析
1、现场还原
在集群重启过程中,不管以什么方式进行重启,避免不了DataNode向NameNode进行BlockReport的交互,从NameNode现场截取两个时间段里部分BlockReport日志。
表1 不同重启方式NameNode处理BR时间统计
| DN Restart Only | - | - | With NN Restart | - | - |
|---|---|---|---|---|---|
| Date | Blocks | ProcessTime | Date | Blocks | ProcessTime |
| 2015-04-28 13:15:51 | 49428 | 646 msecs | 2015-04-28 14:00:57 | 66392 | 73 msecs |
| 2015-04-28 13:15:51 | 49428 | 646 msecs | 2015-04-28 14:00:57 | 66392 | 73 msecs |
| 2015-04-28 13:15:51 | 49068 | 644 msecs | 2015-04-28 14:00:57 | 69978 | 84 msecs |
| 2015-04-28 13:15:52 | 51822 | 638 msecs | 2015-04-28 14:00:57 | 78222 | 98 msecs |
| 2015-04-28 13:15:53 | 83131 | 1214 msecs | 2015-04-28 14:00:57 | 64663 | 71 msecs |
| 2015-04-28 13:15:53 | 90088 | 169 msecs | 2015-04-28 14:00:57 | 85106 | 99 msecs |
| 2015-04-28 13:15:54 | 82024 | 1107 msecs | 2015-04-28 14:00:57 | 87346 | 96 msecs |
| 2015-04-28 13:15:55 | 48114 | 637 msecs | 2015-04-28 14:00:57 | 87802 | 96 msecs |
| 2015-04-28 13:15:55 | 49457 | 84 msecs | 2015-04-28 14:00:57 | 65646 | 71 msecs |
| 2015-04-28 13:15:56 | 82989 | 457 msecs | 2015-04-28 14:00:57 | 71025 | 86 msecs |
| 2015-04-28 13:15:57 | 84634 | 1181 msecs | 2015-04-28 14:00:57 | 66144 | 73 msecs |
| 2015-04-28 13:15:58 | 67321 | 885 msecs | 2015-04-28 14:00:57 | 72652 | 90 msecs |
| 2015-04-28 13:15:59 | 70668 | 924 msecs | 2015-04-28 14:00:57 | 66118 | 76 msecs |
| 2015-04-28 13:15:59 | 73114 | 138 msecs | 2015-04-28 14:00:58 | 67011 | 74 msecs |
| 2015-04-28 13:15:59 | 28215 | 692 msecs | 2015-04-28 14:00:58 | 78216 | 84 msecs |
| 2015-04-28 13:16:00 | 30080 | 321 msecs | 2015-04-28 14:00:58 | 60988 | 66 msecs |
| 2015-04-28 13:16:00 | 30435 | 329 msecs | 2015-04-28 14:00:58 | 52376 | 58 msecs |
| 2015-04-28 13:16:00 | 34350 | 360 msecs | 2015-04-28 14:00:58 | 66801 | 73 msecs |
| 2015-04-28 13:16:01 | 32487 | 344 msecs | 2015-04-28 14:00:58 | 49134 | 53 msecs |
| 2015-04-28 13:16:01 | 28244 | 308 msecs | 2015-04-28 14:00:58 | 66928 | 73 msecs |
| 2015-04-28 13:16:01 | 29138 | 308 msecs | 2015-04-28 14:00:58 | 75560 | 82 msecs |
| 2015-04-28 13:16:02 | 29765 | 301 msecs | 2015-04-28 14:00:58 | 83880 | 92 msecs |
| 2015-04-28 13:16:02 | 28699 | 309 msecs | 2015-04-28 14:00:58 | 82989 | 93 msecs |
| 2015-04-28 13:16:02 | 35377 | 370 msecs | 2015-04-28 14:00:58 | 56210 | 60 msecs |
| 2015-04-28 13:16:03 | 49204 | 626 msecs | 2015-04-28 14:00:58 | 65517 | 78 msecs |
| 2015-04-28 13:16:03 | 27554 | 438 msecs | 2015-04-28 14:00:58 | 76159 | 78 msecs |
| 2015-04-28 13:16:04 | 27285 | 326 msecs | 2015-04-28 14:00:58 | 59725 | 58 msecs |
左半部分记录的是重启全集群DataNode后,NameNode处理单个BlockReport请求耗时,右半部分为重启NameNode后,处理单个BlockReport请求耗时。这里只列了部分数据,虽不具统计意义,但是在处理时间的量级上可信。
从数据上可以看到,对于BlockReport类型的RPC请求,不同的重启方式,RPC的处理时间有明显差异。
2、深度分析
前面也提到从数据上看,对于BlockReport类型的RPC请求,重启全集群DataNode与重启NameNode,RPC处理时间有一个数量级的差别。这种差别通过代码得到验证。
1 2 3 4 5 6 7 | |
可以看到NameNode对BlockReport的处理方式仅区别于是否为初次BlockReport。初次BlockReport显然只发生在NameNode重启期间。
processFirstBlockReport:对Standby节点(NameNode重启期间均为Standby),如果汇报的数据块相关元数据还没有加载,会将报告的块信息暂存队列,当Standby节点完成加载相关元数据后,再处理该消息队列; 对第一次块汇报的处理比较特别,为提高处理效率,仅验证块是否损坏,然后判断块状态是否为FINALIZED状态,如果是建立块与DN节点的映射,其他信息一概暂不处理。
processReport:对于非初次块汇报,处理逻辑要复杂很多;对报告的每个块信息,不仅会建立块与DN的映射,还会检查是否损坏,是否无效,是否需要删除,是否为UC状态等等。
初次块汇报的处理逻辑单独拿出来,主要原因有两方面:
1、加快NameNode的启动时间;统计数据也能说明,初次块汇报的处理时间比正常块汇报的处理时间能节省约一个数量级的时间。
2、由于启动过程中,不提供正常读写服务,所以只要确保正常数据(整个Namespace和所有FINALIZED状态Blocks)无误,无效和冗余数据处理完全可以延后到IBR或next BR。
说明:
1、是否选择processFirstBlockReport处理逻辑不会因为NameNode当前为safemode或者standby发生变化,仅NameNode重启生效;
2、BlockReport的处理时间与DataNode数据规模正相关,当前DataNode中Block数处于:200,000 ~ 1,000,000。
如果不操作NameNode重启,BlockReport处理时间会因为处理逻辑复杂带来额外的处理时间,统计数据显示,约一个数量级的差别。
NameNode对非第一次BlockReport的复杂处理逻辑只是NameNode负载持续处于高位的诱因,在其诱发下发生了一系列“滚雪球”式的异常放大。
1、所有DataNode进程被关闭后,NameNode的CallQueue(默认大小:3200)会被快速消费完;

2、所有DataNode进程被重启后,NameNode的CallQueue会被迅速填充,主要来自DataNode重启后正常流程里的VersionRequest和registerDataNode两类RPC请求,由于均较轻量,所以也会被迅速消费完;

3、之后DataNode进入BlockReport流程,NameNode的CallQueue填充内容开始从VersionRequest和registerDataNode向BlockReport过渡;
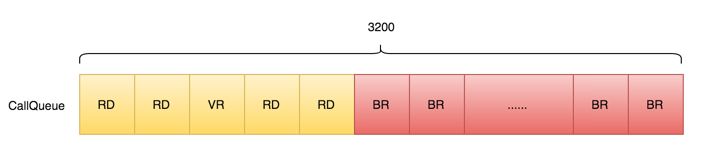
直到CallQueue里几乎被所有BlockReport填充满。
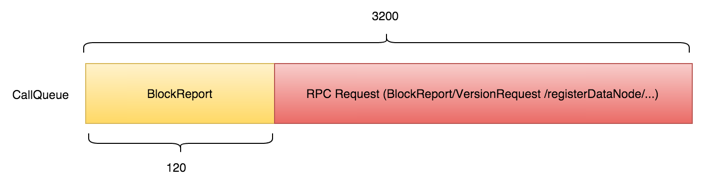
前面的统计数据显示,NameNode不重启对BlockReport的处理时间~500ms,另一个关键数据是Client看到的RPC超时时间,默认为60s;在默认的RPC超时时间范围内,CallQueue里最多可能被处理的BlockReport数~120个,其它均会发生超时。 当发生超时后,Client端(DataNode)会尝试重试,所以NameNode的CallQueue会被持续打满;另一方面,如果NameNode发现RPC Request出现超时会被忽略(可以从日志证实),直到存在未超时的请求,此时从CallQueue拿出来的BlockReport请求虽未超时,但也处于即将超时的边缘,即使处理完成其中的少数几个,CallQueue中的剩余大部分也会出现超时。
1 2 3 4 5 6 7 8 9 | |
通过前面的分析,从整个Timeline上看,NameNode长期处于满负荷运行状态,但是有效处理能力非常低(仅针对BlockReport)。这也是为什么1000+ DataNode(每一个DataNode管理的Block数均未超过1,000,000),也即1000+有效BlockReport请求,在~50min内依然没有被处理完成。
如果DataNode进程处于正常运行状态下,重启NameNode后会发生完全不同的情况。
1、NameNode重启后,首先加载FsImage,此时,除Namespace外NameNode的元数据几乎为空,此后开始接收DataNode过来的RPC请求(绝大多数为Heartbeat);

2、NameNode接收到Heartbeat后由于在初始状态会要求DataNode重新注册;由于Heartbeat间隔是3s,所以从NameNode的角度看,所有DataNode的后续一系列RPC请求会被散列到3s时间线上;

3、DataNode向NameNode注册完成后立即开始BlockReport;由于步骤2里提到的3s时间线散列关系,队列里后半部分BlockReport请求和VersionRequest/registerDataNode请求会出现相互交叉的情况;

4、如前述,处理BlockReport时部分RPC请求一样会发生超时;
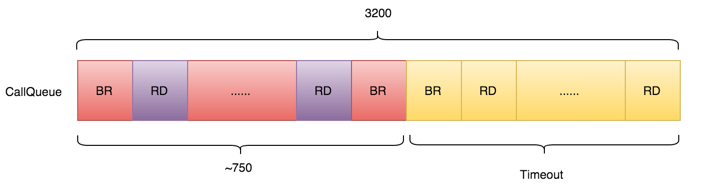
5、由于超时重试,所以部分BlockReport和registerDataNode需要重试;可以发现不同于重启所有DataNode时重试的RPC几乎都是BlockReport,这里重试的RPC包括了VersionRequest/registerDataNode(可以从日志证实),这就大幅降低了NameNode的负载,避免了“滚雪球”式高负载RPC堆积,使异常有效收敛。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
3、避免重启大量DataNode时雪崩
从前面的分析过程,可以得出两个结论:
(1)NameNode对正常BlockReport处理效率是造成可能雪崩的根本原因;
(2)BlockReport的堆积让问题完全失控;
从这两个结论出发可以推导出相应的解决办法:
1、解决效率问题:
(1)优化代码逻辑;这块代码相对成熟,可优化的空间不大,另外所需的时间成本较高,暂可不考虑;
(2)降低BlockReport时数据规模;NameNode处理BR的效率低主要原因还是每次BR所带的Block规模过大造成,所以可以通过调整Block数量阈值,将一次BlockReport分成多盘分别汇报,提高NameNode处理效率。可参考的参数为:dfs.blockreport.split.threshold,默认为1,000,000,当前集群DataNode上Block规模数处于240,000 ~ 940,000,建议调整为500,000;另一方面,可以通过在同一个物理节点上部署多个DataNode实例,分散数据,达到缩小规模的目的,但是这种方案仅能解决当前问题,长期来看依然不能避免,且影响范围比较大,需要多方面权衡。
2、解决堆积问题:
(1)控制重启DataNode的数量;按照当前节点数据规模,如果大规模重启DataNode,可采取滚动方式,以~15/单位间隔~1min滚动重启,如果数据规模增长,需要适当调整实例个数;
(2)定期清空CallQueue;如前述,当大规模DataNode实例被同时重启后,如果不采取措施一定会发生“雪崩”,若确实存在类似需求或场景,可以通过定期清空CallQueue(dfsadmin -refreshCallQueue)的方式,避免堆积效应;这种方案的弊端在于不能有选择的清空RPC Request,所以当线上服务期时,存在数据读写请求超时、作业失败的风险。
3、选择合适的重启方式:
(1)当需要对全集群的DataNode重启操作,且规模较大(包括集群规模和数据规模)时,建议在重启DataNode进程之后将NameNode重启,避免前面的“雪崩”问题;
(2)当灰度操作部分DataNode或者集群规模和数据规模均较小时,可采取滚动重启DataNode进程的方式;
三、总结
1、重启所有DataNode时,由于处理BlockReport逻辑不同,及由此诱发的“雪崩式”效应,导致重启进度极度缓慢;
2、在数据规模达到10K~100K,重启一台DataNode都会给NameNode的正常服务造成瞬时抖动;
3、在数据规模到100K量级时,同时重启~15以内DataNode不会对集群造成雪崩式灾难,但是可能出现短时间内服务不可用状态;
4、全集群升级时,建议NameNode和DataNode均重启,在预期时间内可恢复服务。