一、背景
敏感信息和隐私数据的安全保障是互联网公司非常关心的问题,尤其进入大数据时代,稍有不慎就会出现重大安全事故,所以数据安全问题就变得越来越重要。
Hadoop作为数据平台的基础设施,需要优先关注和解决好安全问题。虽然安全特性对Hadoop非常重要,不过社区直到2011年末随Hadoop-1.0.0才第一次正式发布Hadoop Security,在这之前Hadoop社区版存在较大的安全隐患,需要用户自行解决。
当然数据安全本身是一个复杂的系统工程,想要描述清楚和完美解决几乎不可能。尽管如此,合理有效的安全保障是必要的。本文就Hadoop中数据块安全问题,从设计权衡和实现原理进行简单分析和梳理,简要阐述当前方案在实践中可能遇到的问题,同时提供可借鉴的解决思路。
二、Hadoop安全概述
Hadoop安全需要解决两个问题:
(1)认证:解决用户身份合法性验证问题;
(2)授权:解决认证用户的操作范围问题;
其中认证问题通过Kerberos能够很好地解决,并通过HADOOP-4487在Hadoop内部设计了一套Token机制完美实现了安全认证问题,同时在性能上得到保证,图1为Hadoop安全认证体系概要图示。关于Hadoop Security特性的细节参考HADOOP-4487,这里不再展开。
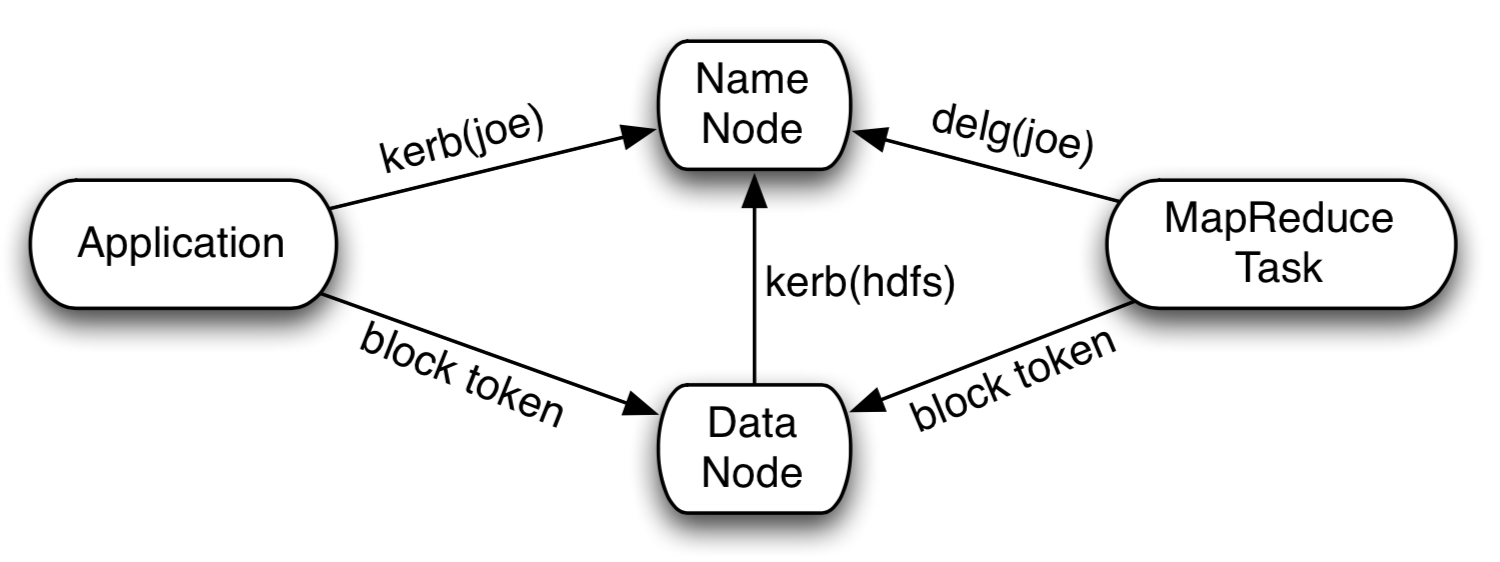
社区针对这个问题在2008.10与Hadoop Security特性同步开始设计BlockToken方案HADOOP-4359,经过半年左右时间在2009.05完成并发布,BlockToken特性可以非常好地保护数据块安全。可以说HADOOP-4487和HADOOP-4359构建起整个Hadoop安全体系,本文重点关注HADOOP-4359。
社区针对这个问题在2008.10与Hadoop Security特性同步开始设计BlockToken方案HADOOP-4359,经过半年左右时间在2009.05完成并发布,通过BlockToken数据块安全问题也得到了很好的解决。可以说HADOOP-4487和HADOOP-4359构建起了整个Hadoop安全体系。
三、安全基础简介
BlockToken方案使用HMAC(Hash Message Authentication Code)[1]技术实现对合法请求的访问认证检查。
HMAC是一种基于HASH函数和共享密钥的消息安全认证协议,它可以有效地防止数据在传输的过程中被截取和篡改,维护数据的安全性、完整性和可靠性。HMAC可以与任何迭代HASH函数结合使用,MD5和SHA-1就是这种HASH函数。实现原理是用公开函数和共享密钥对原始数据产生一个固定长度的值作为认证标识,用这个标识鉴别消息的完整性。使用密钥生成一个固定大小的消息摘要小数据块即HMAC,并加入到消息中一起传输。接收方利用与发送方共享的密钥对接收到的消息进行认证和合法性检查。这种算法不可逆,无法通过消息摘要反向推导出消息,因此又称为单向HASH函数。通过这种技术可以有效保证数据的安全性、完整性和可靠性。
HMAC算法流程: (1)消息传递前,Alice和Bob约定共享密钥和HASH函数; (2)Alice把要发送的消息使用共享密钥计算出HMAC值,然后将消息和HMAC发送给Bob; (3)Bob接收到消息和HMAC值后,使用共享密钥独立计算消息本身的HMAC值,与接收到的HMAC值对比; (4)如果二者的HMAC值相同,说明接收到的消息是完整的,且是Alice发送;
BlockToken方案默认使用了经典的HMAC-SHA1算法,对照前面的流程,Alice代表的是NameNode,Bob代表DataNode,客户端在整个过程中仅作为数据流转的节点。因为HMAC能够保证数据传输过程中不被截取和篡改,只要NameNode给客户端发放了BlockToken,即可认为该客户端申请对单个数据块的访问权限是可信赖的,DataNode只要对BlockToken检查通过就必须接受客户端表述的所有权限。
四、HDFS BlockToken机制
Token机制是整个Hadoop生态里安全协议的重要组成部分,在HDFS内部包括两个部分:
(1)客户端经过初始认证(Kerberos),从NameNode获取DelegationToken,作为后续访问HDFS的凭证;
(2)客户端读写数据前,请求NameNode获取对应数据块Block信息和BlockToken,根据结果向对应DataNode真正请求读写数据。请求到达DataNode端,根据客户端提供的BlockToken进行安全认证检查,通过后继续后续步骤,否则请求失败;
第二部分就是HADOOP-4359和本文主要关注的内容。
4.1 HDFS读写流程
开始详细梳理BlockToken原理之前,首先简单梳理下如图2所示的HDFS读写流程:
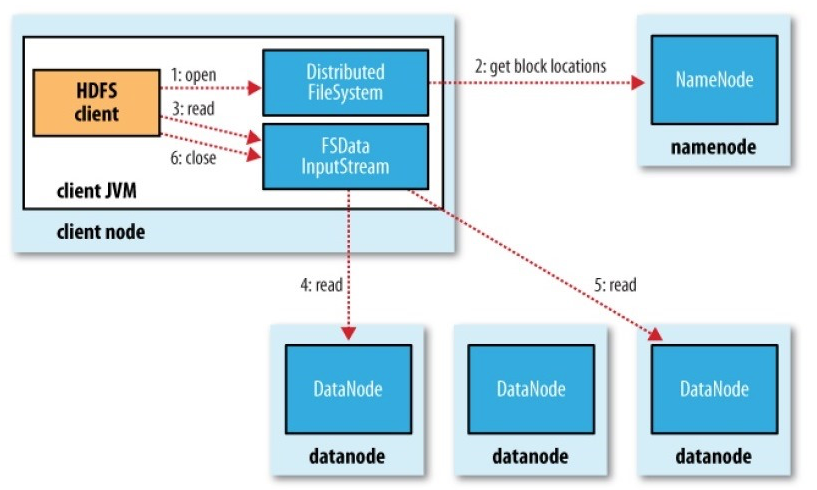
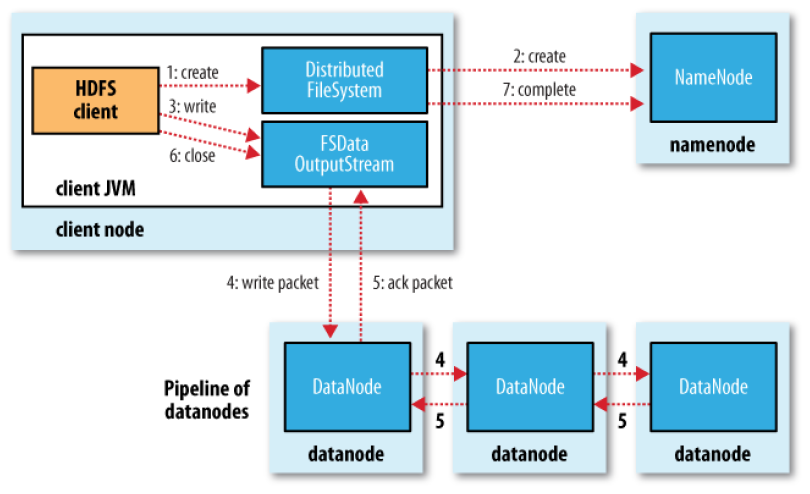
(1)客户端读写操作(open/create)需首先获取数据块Block分布,根据文件路径请求NameNode获取LocatedBlock;
(2)如果是读操作,根据返回LocatedBlock集合,从中选择合适的DataNode进行读数据请求,若需要读取的数据分布在多个Block,按顺序逐个切换到对应DataNode读取;
(3)如果是写操作,首先将返回的LocatedBlock中所有DataNode建立数据管道(Pipeline),然后开始向数据管道里写数据,若写出的数据不能在一个Block内完成,再次向NameNode申请LocatedBlock,直到所有数据成功写出;
(4)读写操作完成,关闭数据流;
LocatedBlock是衔接整个读写流程的关键数据结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
4.2 BlockToken数据结构
前一节提到的LocatedBlock除了标识数据块Block信息外,还包含了认证流程中的核心数据结构blockToken:
1 2 3 4 5 6 7 | |
blockToken的主要属性如下:
(1)kind标识的是Token的类型,这里为常量“HDFS_BLOCK_TOKEN”;
(2)service用来描述请求的服务,一般由服务端的”host:port”组成,对blockToken一般置空;
(3)TokenRenewer在客户端生命周期内周期Renew,避免因为Token过期造成请求失败,对BlockToken未见Renew的显性实现,所以BlockToken只在有效期内生效;
(4)identifier是BlockTokenIdentifier的序列化结果:
1 2 3 4 5 6 7 8 | |
包含了当前请求来源userId,数据块标识blockId,数据块所在的BlockPool(用于HDFS Federation架构),本次请求的权限标识modes(READ, WRITE, COPY, REPLACE),Token的过期时间及keyId;
(5)password即是使用共享密钥SecretKey应用HMAC算法对identifier计算得到的密码。
需要说明的是,keyId和SecretKey存在对应关系,通过keyId可以索引到SecretKey,后续详细介绍。
4.3 BlockToken流程
BlockToken体现在HDFS读写流程的以下几个步骤里:
1、客户端使用文件路径向NameNode发送读写请求,其中请求接口如下:
1 2 | |
2、NameNode经过权限检查后,搜索到文件对应的数据块信息,结合激活的keyId组织出完整的BlockTokenIdentifier,使用keyId对应密钥SecretKey加密BlockTokenIdentifier得到密码,BlockToken数据就绪,加上已经获取到的数据块信息即是LocatedBlock返回给客户端;
3、客户端从NameNode获取到LocatedBlock后,带着BlockToken请求对应DataNode执行数据读写操作;
4、DataNode端接收到读写请求,首先进行BlockToken检查,目的是检查客户端的真实性和权限。主要有两个步骤:
(1)将BlockToken里的identifier反序列化,检查客户端请求的数据块、访问权限及用户名是否与BlockToken的表达一致,如果检查通过进入下一步,否则直接失败;
(2)从identifier反序列化结果里取出keyId,在本地索引对应的共享密钥SecretKey,使用与NameNode端相同的HMAC算法计算password,之后与BlockToken中的password进行比较,如果相等开始真正的数据读写流程,否则请求失败。
上述流程中,NameNode和DataNode计算密码时使用的密钥SecretKey均是以BlockTokenIdentifier.keyid作为索引在本地内存中获取。要想对相同的BlockTokenIdentifier使用同样的加密算法计算得到相同的结果,密钥SecretKey必须完全一致。所以核心问题是,NameNode和DataNode如何保证密钥SecretKey同步,使符合预期的请求通过验证。
最简单的办法就是NameNode和DataNode初始化固定的密钥,到期后NameNode重新生成并同步给DataNode问题解决。
但是事实并没有这么简单,我们知道DataNode与NameNode之间信息交互最频繁的渠道是Heartbeat(默认3s一次),如果NameNode更新了SecretKey,但是DataNode心跳3s后才上报,在这3s时间内,两端存在密钥不一致的问题,也就是在这个时段内即使合法请求也会检查失败,所以“最简单的办法”显然还不能完全解决问题。
虽然“最简单的办法”存在问题,但是提供了一种简单高效解决问题的思路,既然只维护一份共享密钥SecretKey会出现“黑障区”问题,那么同一时刻始终保持两份在线,这样就可以完全避免3s的黑障时间段。
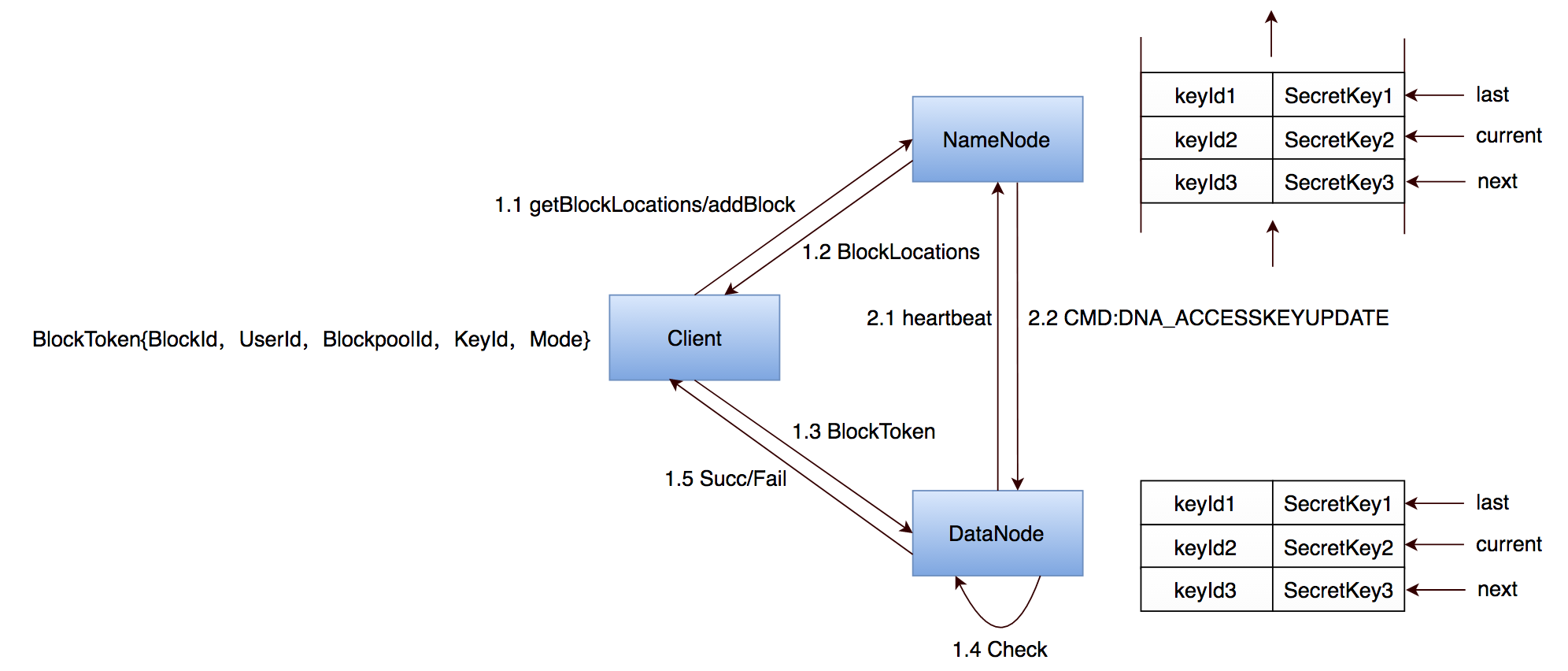
事实上,HDFS更进一步同时维护三份共享密钥,NameNode一旦发现有SecretKey过期,马上生成新SecretKey补充进来并向前滚动当前激活SecretKey,DataNode心跳过来后及时下发更新后的SecretKey集合,如图3所示。维护三份密钥的代价是NameNode需要同时检查三份数据有效期,但是通常情况过期时间较大(默认是10h)且数据量极小,所以完全不会给NameNode或者DataNode带来负担。
4.4 BlockToken密钥HA
前面提到了NameNode和DataNode同步密钥的流程,在HDFS HA架构里通常还存在Active NameNode和Standby NameNode同步数据的问题。
事实上,Active与Standby之间不对SecretKey通过EditLog或其他方式同步。这样带来的新问题是:如何保证操作主从切换后,当前正常读写请求的Token验证通过。如前面提到,NameNode定期更新SecretKey后及时将更新后的SecretKey集合同步给DataNode,DataNode更新以保证正常读写请求通过验证,这种方式对Active和Standby同样适用。所以单从DataNode来看,同一个BlockPool实际上同一时间本地缓存至少6份共享密钥,其中3份来自Active NameNode,另外3份来自Standby NameNode。这样的话,不管客户端请求携带的keyId来自Active NameNode或者Standby NameNode,只要是正常请求均能验证通过,与是否操作主从切换或者从Standby NameNode请求无关。
接下来的问题,DataNode维护了多份<keyId,SecretKey>数据,如何避免来自Active和Standby之间的keyId冲突,以及HDFS Federation架构下,来自多个Namespace的keyId冲突。先来看HDFS Federation架构,与BlockPool类似,共享密钥相关信息也按照这个维度组织就不会相互干扰。来自同Namespace下Active和Standby的keyId确实存在冲突的可能,为了避免出现这种情况,实现时结合Active和Standby的nnId分配独立的keyId序号段即可解决。
除了以上问题,服务重启时还存在其他问题:
(1)NameNode重启:当NameNode重启会重置,由于NameNode重启后所有DataNode需要重新注册,注册完成后返回的CMD指令中包含了NameNode的集合,保证了DataNode与NameNode之间完成同步;
(2)DataNode重启:DataNode重启比较简单,向Active NameNode和Standby NameNode分别注册,成功后会收到Active和Standby的所有集合,更新内存状态即可。
为什么NameNode之间不像其他的WRITE操作,通过EditLog在Active与Standby之间保持同步?原因有两个:
1、SecretKey更新频率很低(10h);
2、数据量非常小(可忽略);
根据这两条不管是NameNode端还是DataNode端都完全可以承载,另外如果通过EditLog同步会增加复杂度,同时如果持久化SecretKey安全性上大打折扣,与Token设计的初衷相悖。
至此,BlockToken的整个流程简单梳理完成,可以看出BlockToken与Kerberos体系的架构和核心流程有很多相似的地方。
五、BlockToken的问题及解决思路
前面BlockToken流程分析可以看出,设计思路和实现方案都比较优雅,但是实践过程中还是可能会遇到一些问题:
(1)NameNode重启完成后DataNode没有成功更新SecretKey造成客户端读写失败;
(2)NameNode滚动SecretKey后DataNode没有及时同步造成后续读写失败;
1 2 3 4 5 6 7 8 9 10 11 12 | |
这两个问题的主要原因是社区实现中DataNode同步SecretKey采用的是从NameNode Push的方案,但是对是否Push成功没有感知,比如:
(1)NameNode重启后,会重新生成新SecretKey集合,DataNode注册时NameNode将所有新生成的SecretKey集合Push给DataNode。我们知道NameNode重启阶段负载非常高,尤其是大规模集群,存在一种情况是NameNode端成功处理了DataNode的注册请求,并将SecretKey集合返回给DataNode,但是DataNode端已经超时没有接收到NameNode的返回结果,这个时候NameNode和DataNode两端出现不一致:NameNode认为DataNode已经成功更新了SecretKey,之后不再下发更新SecretKey命令,但是DataNode端没有接收到新SecretKey集合,依然维护一批无效SecretKey。此后当客户端读写请求过来后,BlockToken验证永远失败;
(2)NameNode滚动SecretKey后,通过Heartbeat的返回值将新SecretKey集合Push给DataNode,同前述场景类似,返回值超时或者DataNode没有接收到心跳的返回值,同样造成NameNode和DataNode两端密钥不一致,默认最长10h后该keyId被激活时,客户端的请求因为BlockToken验证失败同样会读写失败;
前面的两类场景可以看出,问题实际上发生在NameNode向DataNode同步SecretKey,由于采用了Push的方案,但是对结果是否正常并没有感知,两端的数据不一致造成。对应解决方案其实也比较清晰,将NameNode向DataNode同步SecretKey的实现从Push改为Pull,该方案已在社区讨论详见HDFS-13473:
(1)DataNode注册时通过NameNode发下命令更新SecretKey的处理流程保持现状;
(2)在DataNode的心跳中增加当前SecretKey的版本号,NameNode端如果发现与本地SecretKey版本号不匹配通过心跳返回最新SecretKey集合;
将SecretKey同步方式从Push更新到Pull之后,因为心跳间隔默认3s,即使存在单次甚至连续数次心跳处理失败,也可以在接下来成功的请求里及时更新,而不再是必须等默认10h之后才能再次发起同步,而且依然存在更新不成功的可能。可以有效避免NameNode和DataNode两端因为SecretKey不一致造成客户端读写请求失败的问题。
六、总结
本文以Hadoop Security特性背景入手,对HDFS BlockToken方案设计的考虑,社区实现原理,存在的问题和解决思路进行了简单分析和梳理。
通过对BlockToken机制原理和实现细节解析,期望对Hadoop安全窥一斑见全局,对其中可能存在的问题及优化思路提供参考价值。
七、参考
[1] https://en.wikipedia.org/wiki/HMAC
[2] https://issues.apache.org/jira/secure/attachment/12428537/security-design.pdf
[3] https://issues.apache.org/jira/secure/attachment/12409284/AccessTokenDesign1.pdf
[4] https://issues.apache.org/jira/browse/HADOOP-4487
[5] https://issues.apache.org/jira/browse/HADOOP-4359
[6] https://issues.apache.org/jira/browse/HDFS-13473
[7] http://hadoop.apache.org/releases.html