"org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$ReplicationMonitor@254e0df1" daemon prio=10 tid=0x00007f59b4364800 nid=0xa7d9 runnable [0x00007f2baf40b000]
java.lang.Thread.State: RUNNABLE
at java.util.AbstractCollection.toArray(AbstractCollection.java:195)
at java.lang.String.split(String.java:2311)
at org.apache.hadoop.net.NetworkTopology$InnerNode.getLoc(NetworkTopology.java:282)
at org.apache.hadoop.net.NetworkTopology$InnerNode.getLoc(NetworkTopology.java:292)
at org.apache.hadoop.net.NetworkTopology$InnerNode.access$000(NetworkTopology.java:82)
at org.apache.hadoop.net.NetworkTopology.getNode(NetworkTopology.java:539)
at org.apache.hadoop.net.NetworkTopology.countNumOfAvailableNodes(NetworkTopology.java:775)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseRandom(BlockPlacementPolicyDefault.java:707)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:383)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:432)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:225)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:120)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$ReplicationWork.chooseTargets(BlockManager.java:3783)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$ReplicationWork.access$200(BlockManager.java:3748)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.computeReplicationWorkForBlocks(BlockManager.java:1408)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.computeReplicationWork(BlockManager.java:1314)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.computeDatanodeWork(BlockManager.java:3719)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$ReplicationMonitor.run(BlockManager.java:3671)
at java.lang.Thread.run(Thread.java:745)
/** Given a node's string representation, return a reference to the node * @param loc string location of the form /rack/node * @return null if the node is not found or the childnode is there but * not an instance of {@link InnerNode} */privateNodegetLoc(Stringloc){if(loc==null||loc.length()==0)returnthis;String[]path=loc.split(PATH_SEPARATOR_STR,2);Nodechildnode=null;for(inti=0;i<children.size();i++){if(children.get(i).getName().equals(path[0])){childnode=children.get(i);}}if(childnode==null)returnnull;// non-existing nodeif(path.length==1)returnchildnode;if(childnodeinstanceofInnerNode){return((InnerNode)childnode).getLoc(path[1]);}else{returnnull;}}
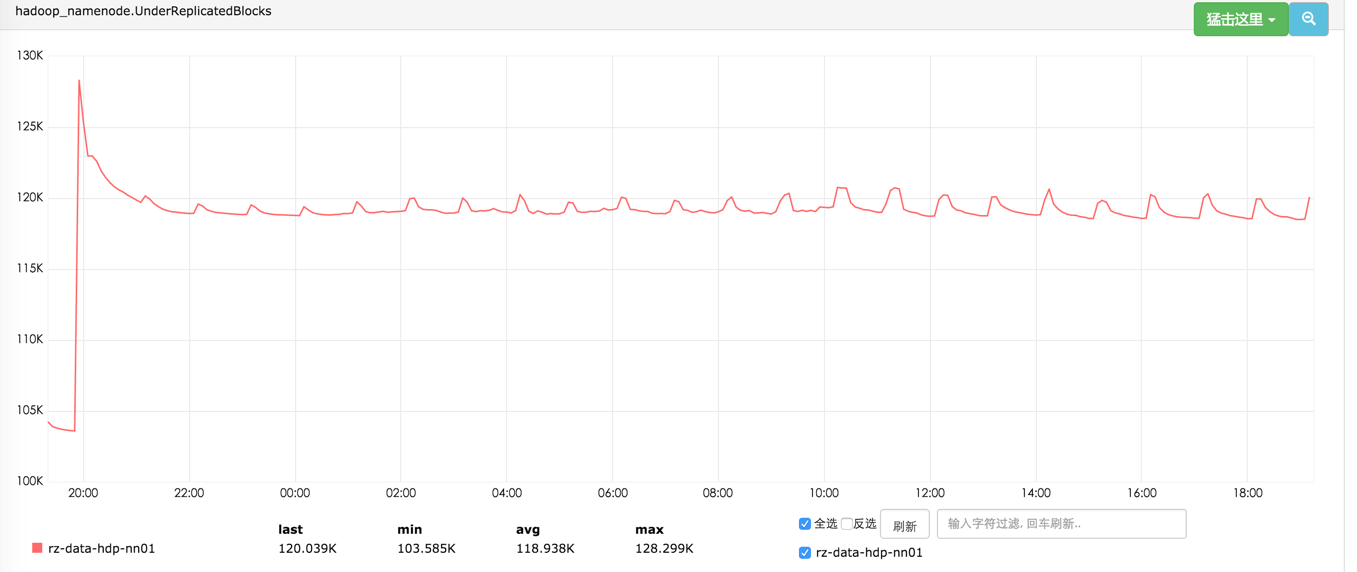
2016-04-19 20:08:52,328 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 7 to reach 10 (unavailableStorages=[], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy
2016-04-19 20:08:52,328 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 7 to reach 10 (unavailableStorages=[DISK], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy
2016-04-19 20:08:52,328 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 7 to reach 10 (unavailableStorages=[DISK, ARCHIVE], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) All required storage types are unavailable: unavailableStorages=[DISK, ARCHIVE], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
2016-04-19 20:08:52,328 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: block = blk_8206926206_7139007477
2016-04-19 20:08:52,328 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: priority = 2
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: srcNode = 10.16.*.*:*
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: storagepolicyid = 0
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: targets is empty
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: exclude = 10.16.*.*:*
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: exclude = 10.16.*.*:*
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: exclude = 10.16.*.*:*
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: exclude = 10.16.*.*:**
<property><name>dfs.namenode.replication.work.multiplier.per.iteration</name><value>5</value></property><property><name>dfs.namenode.replication.max-streams</name><value>50</value><description> The maximum number of outgoing replication streams a given node should have
at one time considering all but the highest priority replications needed.
</description></property><property><name>dfs.namenode.replication.max-streams-hard-limit</name><value>100</value><description> The maximum number of outgoing replication streams a given node should have
at one time.
</description></property>
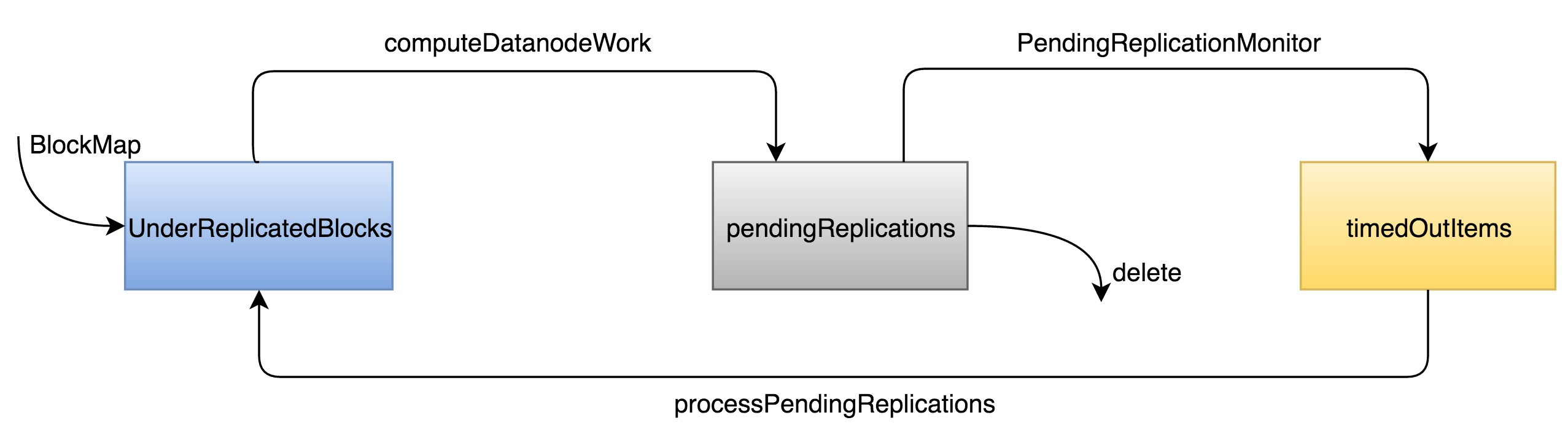
privateclassReplicationMonitorimplementsRunnable{@Overridepublicvoidrun(){while(namesystem.isRunning()){try{// Process replication work only when active NN is out of safe mode.if(namesystem.isPopulatingReplQueues()){computeDatanodeWork();processPendingReplications();rescanPostponedMisreplicatedBlocks();}Thread.sleep(replicationRecheckInterval);}catch(Throwablet){......}}}}
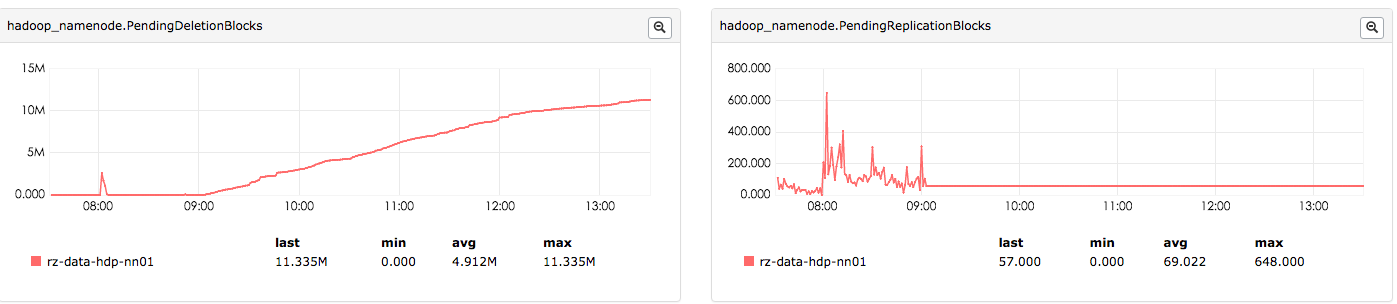
publicvoidremoveBlock(Blockblock){assertnamesystem.hasWriteLock();// No need to ACK blocks that are being removed entirely// from the namespace, since the removal of the associated// file already removes them from the block map below.block.setNumBytes(BlockCommand.NO_ACK);addToInvalidates(block);removeBlockFromMap(block);// Remove the block from pendingReplications and neededReplicationspendingReplications.remove(block);neededReplications.remove(block,UnderReplicatedBlocks.LEVEL);if(postponedMisreplicatedBlocks.remove(block)){postponedMisreplicatedBlocksCount.decrementAndGet();}}
......}finally{namesystem.writeUnlock();}finalSet<Node>excludedNodes=newHashSet<Node>();for(ReplicationWorkrw:work){// Exclude all of the containing nodes from being targets.// This list includes decommissioning or corrupt nodes.excludedNodes.clear();for(DatanodeDescriptordn:rw.containingNodes){excludedNodes.add(dn);}// choose replication targets: NOT HOLDING THE GLOBAL LOCK// It is costly to extract the filename for which chooseTargets is called,// so for now we pass in the block collection itself.rw.chooseTargets(blockplacement,storagePolicySuite,excludedNodes);}namesystem.writeLock();