一、前言
Hadoop 1.0时代,Hadoop核心组件HDFS NameNode和MapReduce JobTracker都存在单点问题(SPOF),其中以NameNode SPOF尤为严重。HDFS作为整个Hadoop生态的基础组件,一旦NameNode发生故障,包括HDFS在内及其上层依赖组件(YARN/MapReduce/Spark/Hive/Pig/HBase等)都将无法正常工作,另外NameNode恢复过程非常耗时,尤其对大型集群,NameNode重启时间非常可观,给HDFS的可用性带来了极大的挑战,同时在使用场景上也带来明显的限制。
Hadoop 2.0时期,Hadoop的所有单点问题基本得到了解决。其中HDFS的高可用(High Availability,HA)在社区经过多种方案的讨论后,最终Cloudera的HA using Quorum Journal Manager(QJM)方案被社区接收,并在Hadoop 2.0版本中发布。
本文将从HDFS HA发展路径,架构原理,实现细节及使用过程中可能遇到的问题几个方面对HDFS NameNode高可用机制(主要是HDFS using QJM,不包含ZKFC)进行简单梳理和分析。
二、HDFS HA发展路径
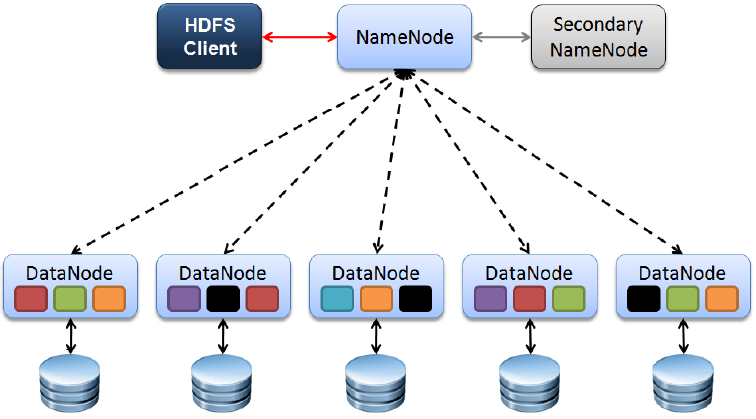
在Hadoop 1.0时代,HDFS的架构相对简单,组件单一,主要包含NameNode,Seconday NameNode,DataNode和DFSClient四个核心组件(见图1 Hadoop 1.0中HDFS架构),其中NameNode提供元数据管理服务,Secondary NameNode以冷备的状态为NameNode分担Checkpoint工作(定期合并FsImage和Editlog),为避免出现歧义后来也称Secondary NameNode为Checkpoint Node。在这种架构下NameNode是整个系统的单点,一旦出现故障对可用性是致命的。
此后,社区讨论过多种HA方案来解决HDFS NameNode的单点问题,其中以2010年Facebook提出的AvatarNode方案(见图2 Facebook提出的HDFS AvatarNode架构图)较为典型。在AvatarNode方案中使用Avatar Primary NameNode,Avatar Standby NameNode及NFS配合通过共享的方式管理HDFS部分元数据EditLog。其中Avatar Primary NameNode提供读写服务,并将Editlog写入到共享存储NFS上,Avatar Standby NameNode从共享存储NFS上读取Editlog数据并回放,这样尽可能保持与Primary之间状态一致。
AvatarNode方案第一次使HDFS NameNode具备了热备能力,一旦Primary NameNode出现故障,Avatar Standby NameNode可以在极短时间内接管HDFS的读写请求,真正实现了HDFS的高可用。
但是AvatarNode这种方案并不是完美的。它的问题主要是共享存储NFS成为新的SPOF,必须保证其高可用;同时AvatarNode不具备自动Failover能力,一旦Avatar Primary NameNode出现故障,需要运维人员介入手动处理,当然Facebook这样设计有自己的考虑,这里就不再展开;另外一点,昂贵的NFS设备引入与HDFS最初构建在“inexpensive commodity hardware”设计初衷多少有些出入。
虽然存在问题,但是AvatarNode架构相比Hadoop 1.0已经有了本质的区别,也正是因为其在HA特性上的优秀表现,AvatarNode方案被国内外很多团队采纳和使用。
2012年初,Cloudera工程师Todd Lipcon主导设计的HA using QJM方案进入社区(见图3 HDFS HA using QJM架构图)。
QJM的思想最初来源于Paxos协议,摒弃了AvatarNode方案中的共享存储设备,改用多个JournalNode节点组成集群来管理和共享EditLog。与Paxos协议类似,当NameNode向JournalNode请求读写时,要求至少大多数(Majority)成功返回才认为本次请求成功。对于一个由2N+1台JournalNode组成的集群,可以容忍最多N台JournalNode节点挂掉。从这个角度来看,QJM相比AvatarNode方案具备了更强的HA能力。
同时QJM方案也继承了社区早前实施过的HA方案中优秀特性,通过引入Zookeeper实现的选主功能,使NameNode真正具备了自动Failover的能力。
对比AvatarNode,HA using QJM方案不再存在SPOF问题,High Availability特性明显提升,同时具备了自动Failover能力。正是其良好的设计和容错能力,HDFS HA using QJM方案在2012年随Hadoop 2.0正式发布,此后一直是Hadoop社区默认HDFS HA方案。
当然除了上面提到两种典型的HDFS HA方案外,社区其实在HA特性上进行过多次尝试。
开始于2008年,并随Hadoop 0.21发布的BackupNode方案(参考:HADOOP-4539);2011年通过单独分支HDFS HA Branch开发的功能非常丰富的HDFS HA方案,并在Hadoop 0.23发布(参考:HDFS-1623),其中LinuxHA和BookKeeper方案都出自这里;等等不一而足。
三、HA using QJM原理
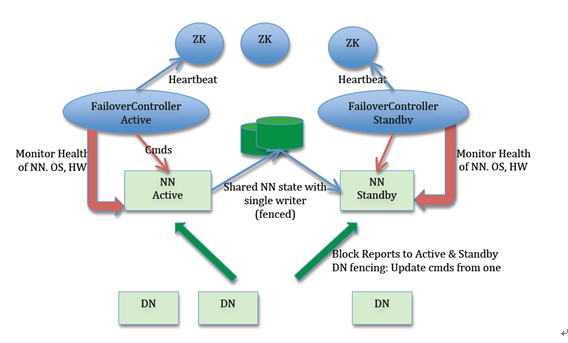
3.1 HA using QJM架构
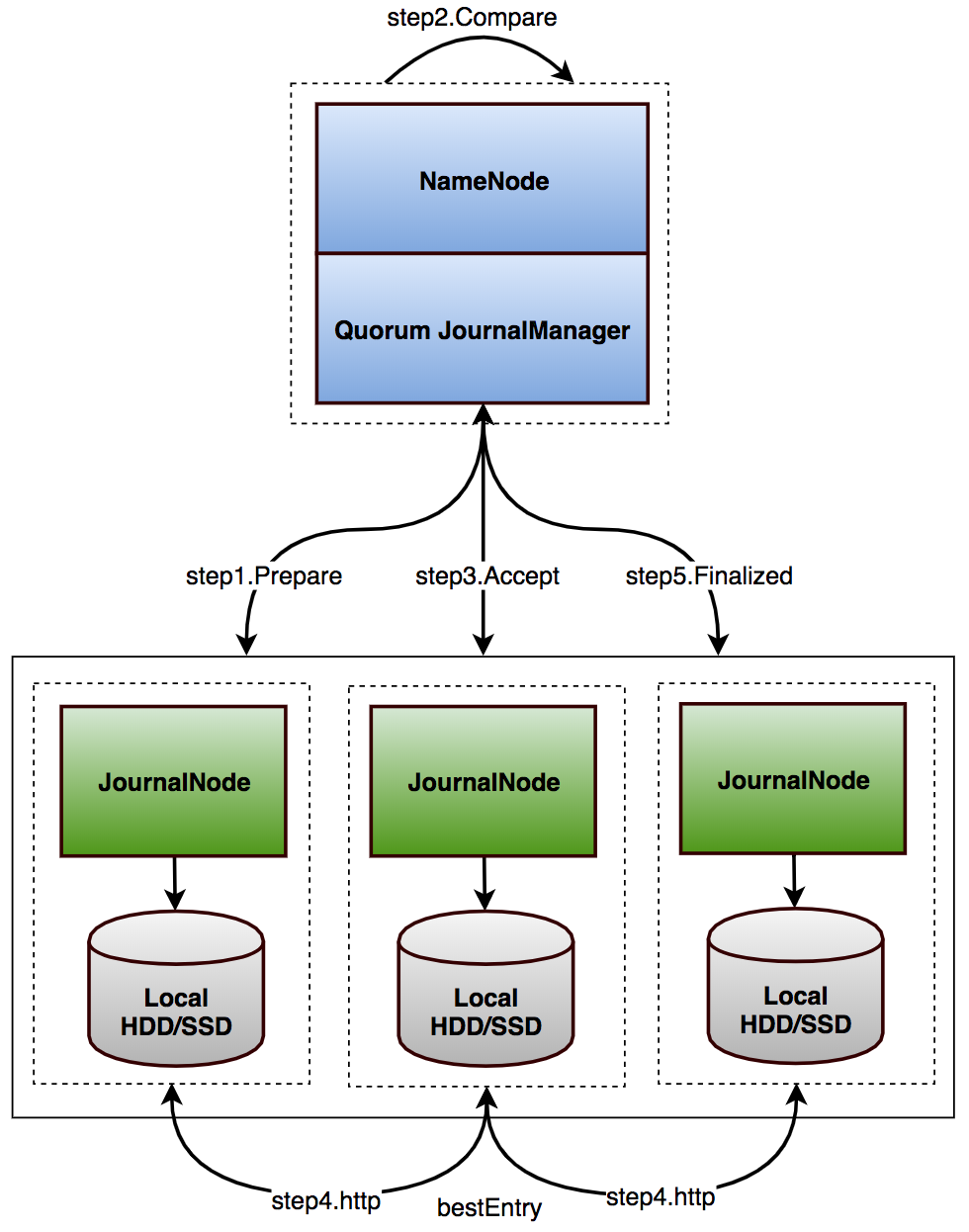
HA using Quorum Journal Manager (QJM)是当前主流HDFS HA方案,由Cloudera工程师Todd Lipcon在2012年发起,随Hadoop 2.0.3发布,此后一直被视为HDFS HA默认方案。
在HA using QJM方案中,涉及到的核心组件(见图3)包括:
Active NameNode(ANN):在HDFS集群中,对外提供读写服务的唯一Master节点。ANN将客户端请求过来的写操作通过EditLog写入共享存储系统(即JournalNode Cluster),为Standby NameNode及时同步数据提供支持;
Standby NameNode(SBN):与ANN相互形成热备,SBN及时从共享存储系统中读取EditLog数据并更新内存,以保证当前状态尽可能与ANN同步。当前在整个HDFS集群中最多一台处于Active状态,最多一台处于Standby状态;
JournalNode Cluster(JNs):ANN与SBN之间共享Editlog的一致性存储系统,是HDFS NameNode高可用的核心组件。借助JournalNode集群ANN可以尽可能及时同步元数据到SBN。其中ANN采用Push模式将EditLog写入JN,SBN通过Pull模式从JN拉取数据,整个过程中JN不主动进行数据交换;
ZKFailoverController(ZKFC):ZKFailoverController以独立进程运行,对NameNode主备切换进行控制,正常情况ANN和SBN分别对应各自ZKFC进程。ZKFC主要功能:NameNode健康状况检测;借助Zookeeper实现NameNode自动选主;操作NameNode进行主从切换;
Zookeeper(ZK):为ZKFC实现自动选主功能提供统一协调服务。
需要说明的是,在HA using QJM架构下,DataNode从仅向单个NameNode进行数据交互升级到同时向ANN和SBN进行数据交互,区别是仅执行ANN下发的指令,其他逻辑未发生大变化。
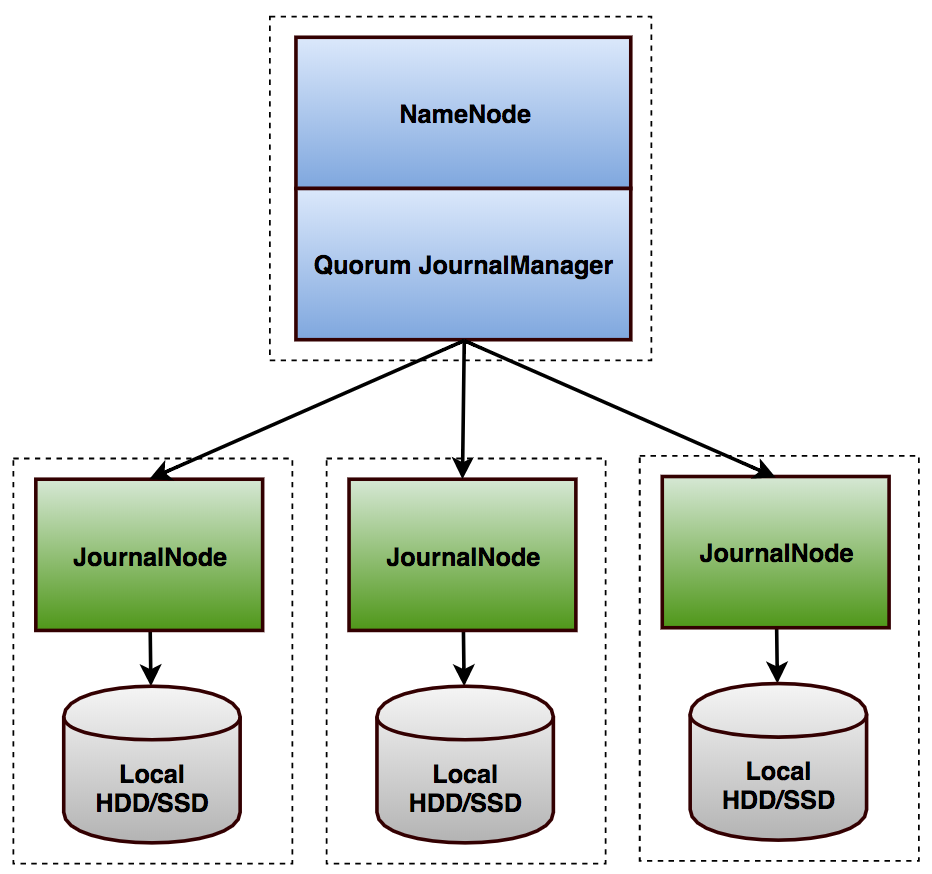
3.2 JournalNode Cluster实现
前面提到NameNode与JournalNode Cluster进行数据读写时核心点是需要大多数JN成功返回才可认为本次请求有效。所以同Zookeeper部署类似,实际部署JournalNode Cluster时也建议奇数节点(大多数场景选择3~5个)。当然奇数节点并非强制,事实上偶数节点组成的JournalNode Cluster也能工作,但是极端的情况会存在问题,比如活锁(原理和细节可参考Paxos made simple[2]),所以不建议这么做。
在JournalNode Cluster中所有JN之间完全对等,不存在Primary/Secondary区别。功能上看也极其简单,Hadoop-2.7.1分支中总共2478行代码实现了完整的JournalNode功能,详细模块见图4JournalNode功能模块。
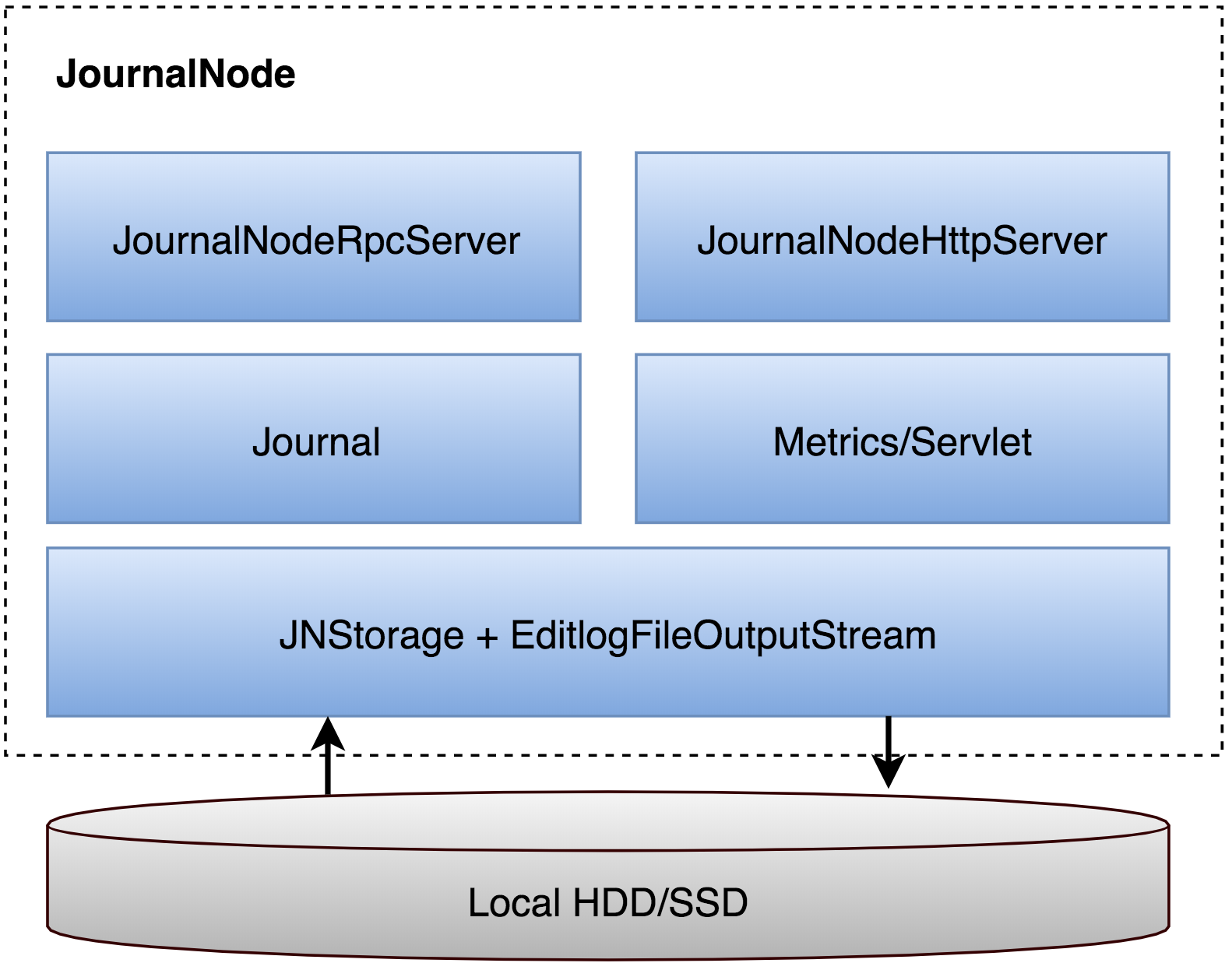
JournalNode对外提供RPC和HTTP两类数据服务接口,其中JournalNodeHttpServer提供的HTTP服务,除暴露常规Metrics信息外,同时提供了被动Editlog数据同步功能(后面会详细介绍)。JournalNodeRpcServer提供的RPC Server,为NameNode向JournalNode的数据读写和状态获取请求准备了完备的RPC接口,详见QJournalProtocol.proto。Journal模块是JournalNodeRpcServer的具体实现,在Journal模块里,除了简单维护JournalNode状态信息,核心实现是抽象底层存储介质的读写操作。
整体上看,JournalNode模块清晰,实现简单,其中有几处非常讨巧的实现:
1、为了降低读写操作相互影响,Journal采用了DoubleBuffer技术管理实时过来的Editlog数据,通过DoubleBuffer可以为高速设备(内存)与低速设备(磁盘/SSD)之间建立缓存区和管道,避免数据写入被低速设备阻塞影响性能;
2、NameNode到JournalNode的所有数据写入请求都会直接落盘,当然写入请求的数据可以是批量,只有数据持久化完成才能认为本次请求有效和成功,这一点在数据恢复时非常关键;
3、与Pasox/Zookeeper类似,所有到达JournalNode的读写请求,第一件事情是合法性校验,包括EpochNum,CommitTxid等在内的状态信息,只有校验通过才能被处理,状态校验是强一致保证的基础;
一句话总结JournalNode是一套提供读写服务并实时持久化序列数据的有状态存储系统。
3.3 Active NameNode端实现
整个HA using QJM方案核心部分都集中在NameNode端,也可以认为是QJournal的Client端,这里集中了所有关于数据一致性保证和状态合理转换的主要内容。其中Active NameNode因为是写入端,所以实现逻辑也较复杂。
ANN按照响应客户端写请求的粒度实时顺序持久化到JournalNode,也是ANN请求JournalNode的最小粒度FSEditLogOp(HDFS写操作序列化数据)。这里首先需要权衡关于如何在JournalNode落地数据的问题:
1、将所有的FSEditLogOp数据落到同一个文件;
2、将每一条FSEditLogOp数据落到一个文件;
3、折中方案;
前面已经提到,QJournal必须保证完整事务和数据一致性,这就要求具备数据恢复的能力。如果将所有FSEditLogOp都落到一个文件,势必会带来管理成本上额外的开销,一旦出现数据不一致情况恢复大文件的代价非常高,同时同一文件累计了大量事务请求,写入失败风险非常高(后续会详细介绍);另一种极端情况是对每一条FSEditLogOp写入一个文件,这种方式在容错和数据异常恢复会非常方便,但显然读写效率极差。所以必须对两种极端情况做折中(计算机领域内大多问题都在tradeoff)。
按照前面的分析,折中的唯一办法就是对连续FSEditLogOp进行分段管理。事前给每一条FSEditLogOp分配唯一且连续的事务ID称为txid,连续多个txid组成Segment,Segment持久化后对应一个EditLog文件,这样一来,任何时间JournalNode上有且仅有一个Segment处于Inprogress状态,其他均为Finalized状态。即使存在数据不一致仅需恢复Inprogress状态的Segment,Finalized Segment一定是大多数JournalNode成功写入。这样权衡可以较好解决两种极端情况的问题。
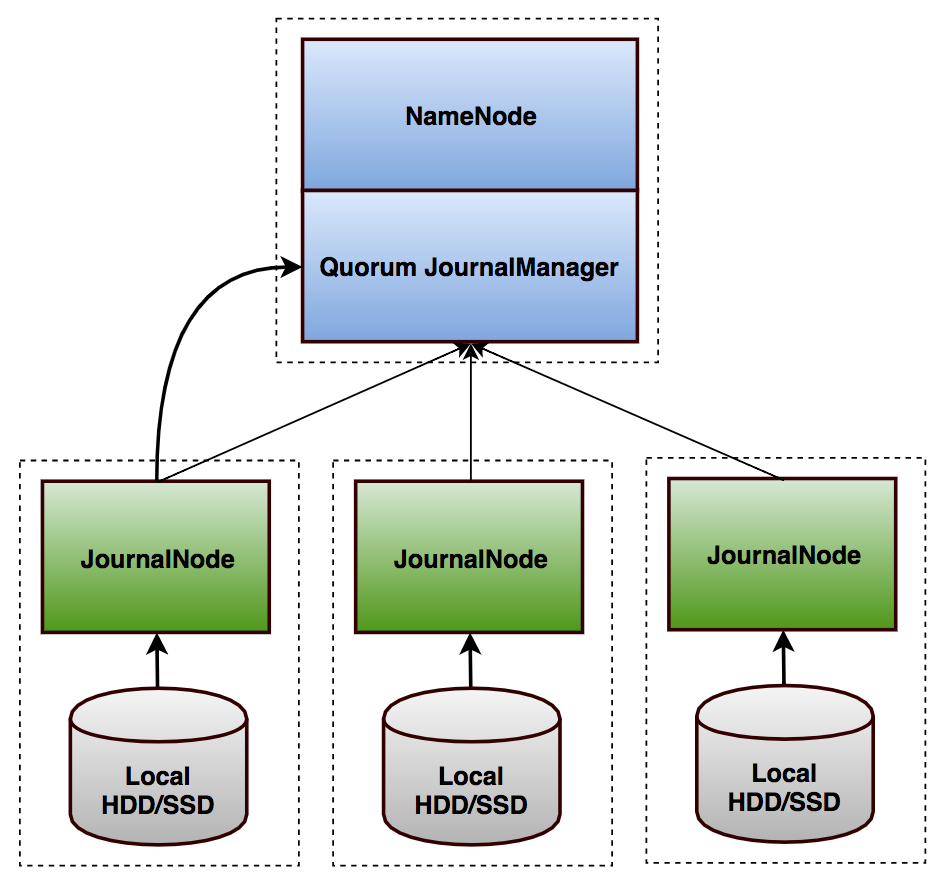
在ANN进程的整个生命周期里,按照不同阶段,与JournalNode交互的逻辑可以简单划分成三个部分,如图5所示Active NameNode与JournalNode之间交互的状态转换图。
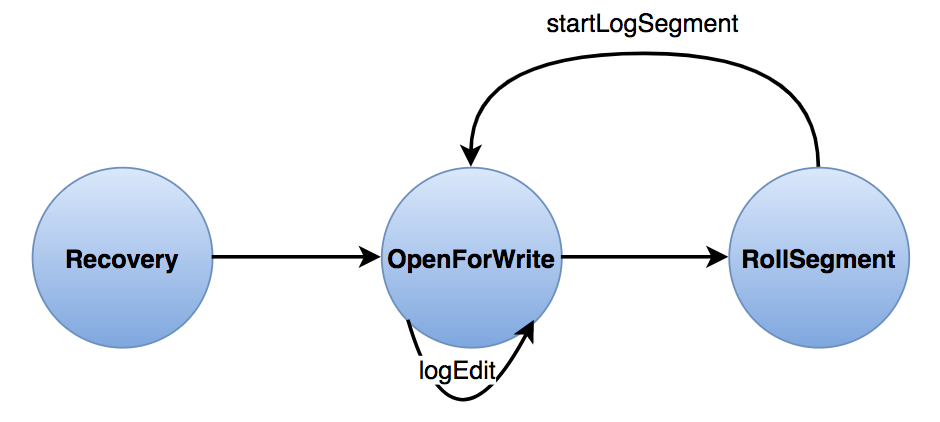
ANN与JournalNode在整个过程中RPC交互非常频繁,所有RPC请求均采用异步的方式,NameNode端只要收到大多数的JournalNode请求响应即认为本次请求成功,如果部分JournalNode请求失败或者超时该节点将在当前Segment内被置为异常节点。
Recovery
QJournal继承了Paxos一致性模中的EpochNum技术,每次做主从切换时,尝试切换为Active的NameNode从JournalNode端读取当前的EpochNum,自增1后尝试写入JournalNode。当出现多个NameNode均尝试切换为Active时会因为EpochNum问题最多只有一个成功,这从Qjournal的角度可以彻底杜绝出现Brain-Split问题。
NameNode操作主从切换后,首先需要确认所有JournalNode上的Editlog数据保持同步,前面提到只有最后一个Segment可能出现不一致情况,之后才能从JournalNode上拉取最新未同步的Editlog,更新内存以达到最新状态。其中保证所有JournalNode的Segment同步即是Recovery过程,整个过程如图6。
1、NameNode向JournalNode请求获取当前Epoch,从结果中选取出最大的Epoch;
2、将最大的Epoch自增1后尝试请求写入JournalNode;
如前述,以上两步可以在QJournal防止NameNode Brain-Split。这种竞争写入的方式可以保证任意时间最多只能存在一个NameNode有能力写入JournalNode,也是QJournal强一致的基础(关于该算法强一致性模型的形式化证明可参考Paxos made Simple[2])。
3、向JournalNode请求获取最新Segment的起始事务编号(txid),具体实现时这个步骤与前一步合并,可以减少一次RPC请求;
4、取前一步所有返回的txid最大值segmentTxId作为本次Recovery输入进入数据恢复阶段(特殊情况是集群刚初始化时,所有的JournalNode实际上并没有Segment文件,所以数据恢复可直接跳过,判断是否需要做数据恢复的条件是有没有取到txid):
(1)向JournalNode请求PrepareRecovery,参数是segmentTxId,JournalNode根据自己的实际情况返回满足起始txid为segmentTxId的Segment信息:{startTxId, endTxId, isInProgress},分别描述了起始事务编号,最后事务编号及当前Segment是否Inprogress;
(2)根据SegmentRecoveryComparator算法选择所有JournalNode中最优Segment(bestSegment)准备执行Recovery;(SegmentRecoveryComparator算法:优先选择Finalized Segment,再次选择JournalNode端可见最大Epoch的Segment,最后比较endTxId最大者)
(3)使用前一步选出的bestSegment组装出可定位到该Segment(hostname + NamespaceInfo + segmentTxId)的URL(具体JournalNode存储Segment的位置),使用URL作为输入向JournalNode请求AcceptRecovery,当JournalNode接收到AcceptRecovery请求后,经过合法性和URL简单检查,包括startTxId,endTxid是否与本地数据存在包含关系等,通过后拿URL通过HTTP请求将目标JournalNode的Segment拉到本地,并替换本地最新一个Segment,到这里所有JournalNode上的Editlog基本一致;之所以这么说是因为最后一个Segment的数据确实是完全同步的,但是已经Finalized的Segment只能保证大多数JournalNode之间完全一致。
(4)请求JournalNode将最新Segment操作Finalized,最后一步操作相当于跟之前写入的数据彻底“划清界限”;
到这里完成了第一阶段对JournalNode数据一致性检查和修复;
5、NameNode进入数据更新阶段,因为有前面一致性检查和修复,另外FsImage也记录过其对应到的txid,这个阶段只要从JournalNode取回该txid之后写入的数据回放一遍,内存状态即可达到最新,这个过程称为TailEdits;当然回放完成后需要记录nextTxId,为开启ANN写操作做准备;
6、到这里基本具备了开放读写服务的能力,因为前面已经将所有的Segment操作了Finalized,所以开启新的Segment,即请求JournalNode初始化新Segment,并建立到JournalNode的长连接管道startLogSegment,以便数据实时写入;
所有的准备工作完成,NameNode正式进入Active状态,开启HDFS读写服务。
Log Synchronization
ANN正式开启读写服务后,所有读请求在NameNode端即可完成,但是写请求需要实时同步给JournalNode,以便SBN能够及时读取并回放,以保持与Active几乎接近的状态。
ANN写FSEditLogOp的整体流程如图7所示:
1、首先在ANN处理客户端写请求的最后一个阶段,根据当前的请求类型和请求参数及当前的txid组成FSEditLogOp;
2、ANN端将FSEditLogOp写入到DoubleBuffer,这个阶段在NameNode整个FSNamesystem锁内,所以在任意时间仅有唯一的线程可以写入数据。可以看到DoubleBuffer技术在NameNode和JournalNode端均有使用,这里使用的目的与前面讲过的原因基本相当,一方面为低速设备(网络通道)和高速设备(内存)之间建立缓存区和管道,另一方面DoubleBuffer也可以降低锁的粒度,以到达更好的性能;
3、ANN处理客户端写请求的锁外,NameNode请求执行一次对FSEditLogOp的Sync操作,也就是说NameNode端写缓存是单线程操作,但是Sync可能是批量操作,但是从客户端角度来看写请求都会保证数据安全落到JouranlNode后才会返回,所以整体上看NameNode具备强一致性保证,当然整个文件系统强一致保证由多个部分共同支撑,这里不再展开。ANN端的Sync首先从DoubleBuffer里读出所有准备就绪的数据,通过RPC请求送达JournalNode,这类请求到达JournalNode端会第一时间持久化,保证数据可靠;
RollEditLog
前面也提到,单个Segment不可能无限大,是按照区间进行划分的,当然这个区间的划分一定不只有一条标准,默认情况下,ANN端内独立线程每间隔5min做一次检查,如果当前累计写入的FSEditLogOp超过2,000,000条操作Segment滚动,可以看到,事实上这个区间的大小可能会超出2,000,000(每间隔5min检查一次),ANN内的检查机制是为了防止SBN不工作时的补偿机制。
当然,请求执行RollEditLog不单单ANN端的线程,事实上SBN也会触发RollEditLog,SBN默认每1min操作执行一次EditLog回放,在回放EditLog前如果发现超过两分钟没有RollEditLog且期间有新增的FSEditLogOp,先请求ANN强制进行RollEditLog。在正常情况下,通过SBN请求执行RollEditLog是控制Segment规模的直接方法。
RollEditLog与前面的Recovery过程最后一步类似,首先将当前正在写入Segment操作Finalized,然后请求JournalNode初始化新Segment,建立到JournalNode的长连接管道并startLogSegment。
3.4 Standby NameNode端实现
SBN作为ANN的热备,需要尽可能保持与ANN状态一致,做好随时接管ANN任务的准备。当然在不损失一致性保证的前提下如果能分担ANN的部分请求处理会更好。
如前述,SBN为了保持与ANN状态接近甚至一致,默认每间隔1min回放一次EditLog,回放的第一步是从合适的JournalNode拉取Segment。
在Active NameNode端实现一节已经提过ANN写到JournalNode的Segment包含了startTxId和endTxId,所以SBN每回放完一个Segment会记录当前已经回放到的txid。这为接下来继续拉取Segment提供了起始位置,也是本次从JournalNode拉取数据的唯一输入。
首先,SBN根据当前的txid+1从JournalNode端获取所有包含了txid+1或者startTxId大于txid+1的Segment列表;
之后,根据取回Segment集合做简单过滤和排序,过滤是为了找到更合适的Segment,比如相同txid集合的Segment,回放Finalized更安全;保留多个Segment并排序是为了更好的容错;
最后,按照已排好序Segment,逐个FSEditLogOp尝试取Segment内容,按照FSEditLogOp粒度读取并回放,直到改Segment回放完成;
当前实现中,SBN仅回放Finalized状态的Segment。
3.5 数据一致性保证
从前面的分析来看,QJM本质上是一种极其简化版的Paxos协议,所以基本具备了Paxos优势。如果按照分布式系统经典理论CAP来评估,QJM是一种强一致性、高可用的去中心化分布式协议。
高可用:QJM的高可用特性其实是完全继承自Paxos,但在具体实现中为实现强一致性实际上牺牲了少部分高可用性。Paxos中Quorum理论在QJM依然稳定,也就是对于JournalNode Cluster,最多可以容忍小于一半的节点故障,系统仍可正常运行。但是如前面提到为了实现强一致性,QJM放大了故障范围(只要出现一次请求响应失败或者超时即标记该JournalNode在当前Segment范围内失效outOfSync),而且对于故障完全没有恢复能力,虽然通过限定Segment范围尽力补救故障影响范围,但是不可否认因为故障被放大,且没有恢复机制,不可用的风险同故障范围被线性放大。
高度去中心化:前面的流程分析过程不难看出,JournalNode整个生命周期,仅初始化阶段由ANN触发过一次选主以及JournalNode间的交互过程,其他阶段JournalNode之间完全对等,完全无中心化节点,这样也就不存在SPOF的问题,所以也具备了非常好Partition Tolerance特性。
强一致性:
1、强一致性是Paxos及各衍生系统最明显的优势特性,QJM的一致性思想主要来源于Paxos,另外为了达到更好的性能,在Pasox基础上又放松了很多限制条件。比如相比Paxos仅需要竞争一次,完成后继承结果,不需要为强一致每一轮数据读写都先竞选影响性能,从这个角度看,QJM与Raft也有相似的特征(是不是存在更本质一致性算法);当然,QJournal放松诸多限制条件跟HDFS的使用场景强相关,比如最多只存在两个QJournal Client,竞争发生的条件非常严苛,即使极端情况产生竞争也能够在一轮竞选完成;
2、延后读保证数据强一致,SBN当前仅读取和回放Finalized状态Segment,可以保证Finalized数据强一致,借鉴Paxos思想在数据恢复阶段可以做到Inprogress状态数据强一致,同时QJM采用了一种尽力而为的恢复机制,对不确定状态定义了统一恢复策略;
3、全局有序和递增的Epoch序号,任意时间仅一个竞争者(QJournal Client即NameNode)胜出,保证写入端的唯一性和合法性。
四、QJM的问题及解决思路
虽然HA using QJM方案作为HDFS默认HA方案已经在社区稳定运行了超过5年时间,但实际上还是存在一些问题:
1、Paxos算法在出现竞争时,收敛速度慢,甚至可能出现活锁的情况,QJM并没有针对这种问题进行过优化。极端情况下如果出现两个NameNode同时竞争写入,也可能陷入僵局,虽然不至于污染数据(Brain-Split),但是存在永远竞争陷入僵局的可能。
2、QJM放大了故障范围,且在Segment周期里没有任何恢复机制,虽然通过限制Segment大小进行了补偿,但是风险被线性放大,尤其对JournalNode小集群及配置Segment较大事务区间;
3、在线升级JournalNode让QJournal可用性风险成倍放大,原因同问题2;
4、QJM对JournalNode在单Segment故障没有恢复机制,ANN一旦遇到写入失败,只能操作主从切换甚至重启,对规模较大的Hadoop集群,重启NameNode成本非常高;
针对上述问题,实际上业界已有一些对应的解决办法,不过需要强调的是所有解决办法都在尽力权衡CAP:
1、对于Paxos在竞争情况下收敛慢和活锁问题,在HDFS场景里出现的概率极小,而且最多只有两个竞争者,且两个竞争者同时出现的唯一可能是误操作尝试将两个NameNode均切换成ANN,这种问题应该尽可能在运维中避免;从技术的角度看,虽然可以通过Leader选择,加快收敛速度和避免活锁,但是在HDFS场景下为解决极端情况牺牲可用性是否有必要值得商榷;
2、JournalNode故障快速恢复完全可以借鉴RollEditLog的办法,增加触发RollEditLog的条件,同时需要考虑Journal出现故障后频繁RollEditLog带来的性能损失;
3、实际场景里,最需要解决的还是NameNode因为Journal写入失败造成进程退出的问题,可借鉴的方案也很多,这里列出两种代价较小方案供参考: (1)所有Journal写入失败,强制NameNode退出竞争者,进入Standby状态; (2)延长请求JournalNode超时时间,用损失极端情况下性能损失换取NameNode重启成本;
五、总结
本文从HDFS HA的发展过程,各种方案设计背后的考虑,以及社区选择的默认HA using QJM方案原理和其中存在的问题及解决思路简单分析。
通过QJM原理梳理和实现细节分析,可以深入理解HDFS HA现状和存在问题,为后续运维甚至优化改进积累经验。
六、参考
[1] https://hadoop.apache.org
[2] https://www.microsoft.com/en-us/research/publication/paxos-made-simple/
[3] http://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
[4] https://issues.apache.org/jira/secure/attachment/12435811/AvatarNodeDescription.txt
[5] http://www.cloudera.com/blog/2009/07/hadoop-ha-configuration/
[6] http://www.cloudera.com/blog/2012/03/high-availability-for-the-hadoop-distributed-file-system-hdfs/
[7] http://zookeeper.apache.org/bookkeeper/
[8] https://github.com/apache/hadoop/tree/branch-2.7.1
[9] https://issues.apache.org/jira/browse/HDFS-3077
[10] https://issues.apache.org/jira/browse/HDFS-1623
[11] https://issues.apache.org/jira/browse/HADOOP-4539
[12] https://issues.apache.org/jira/browse/HDFS-976