一、背景
众所周知,NameNode全局锁(FSNamesystemLock)问题一直是制约HDFS性能尤其是NameNode处理能力的主要原因。为此,社区和业界经过多次尝试,试图解决NameNode全局锁问题,但是从结果来看,都不理想。
本文将首先梳理NameNode当前的锁机制以及解决全局锁问题所面临的困难,结合经典分布式文件系统在这个问题上的一般解法,尝试给出可能的解决思路。
二、全局锁机制
NameNode是整个HDFS的核心组件[1],集中管理HDFS集群的所有元数据,主要包括文件系统的目录树、数据块集合和分布以及整个集群的拓扑结构。
同GFS一样HDFS采用了”一次写多次读“的读写模型来满足离线数据处理场景的存储需求,在此基础上,进一步放松一致性模型简化文件系统。在具体实现上,相比GFS1.0,HDFS做了更大胆取舍,锁机制上使用全局锁来统一来控制并发读写。这样处理的优势非常明显,全局锁进一步简化锁模型,不需要额外考虑锁依赖关系,同时降低复杂度,减少工程量。但是问题比优势更加突出,核心问题就是全局唯一锁制约性能提升。
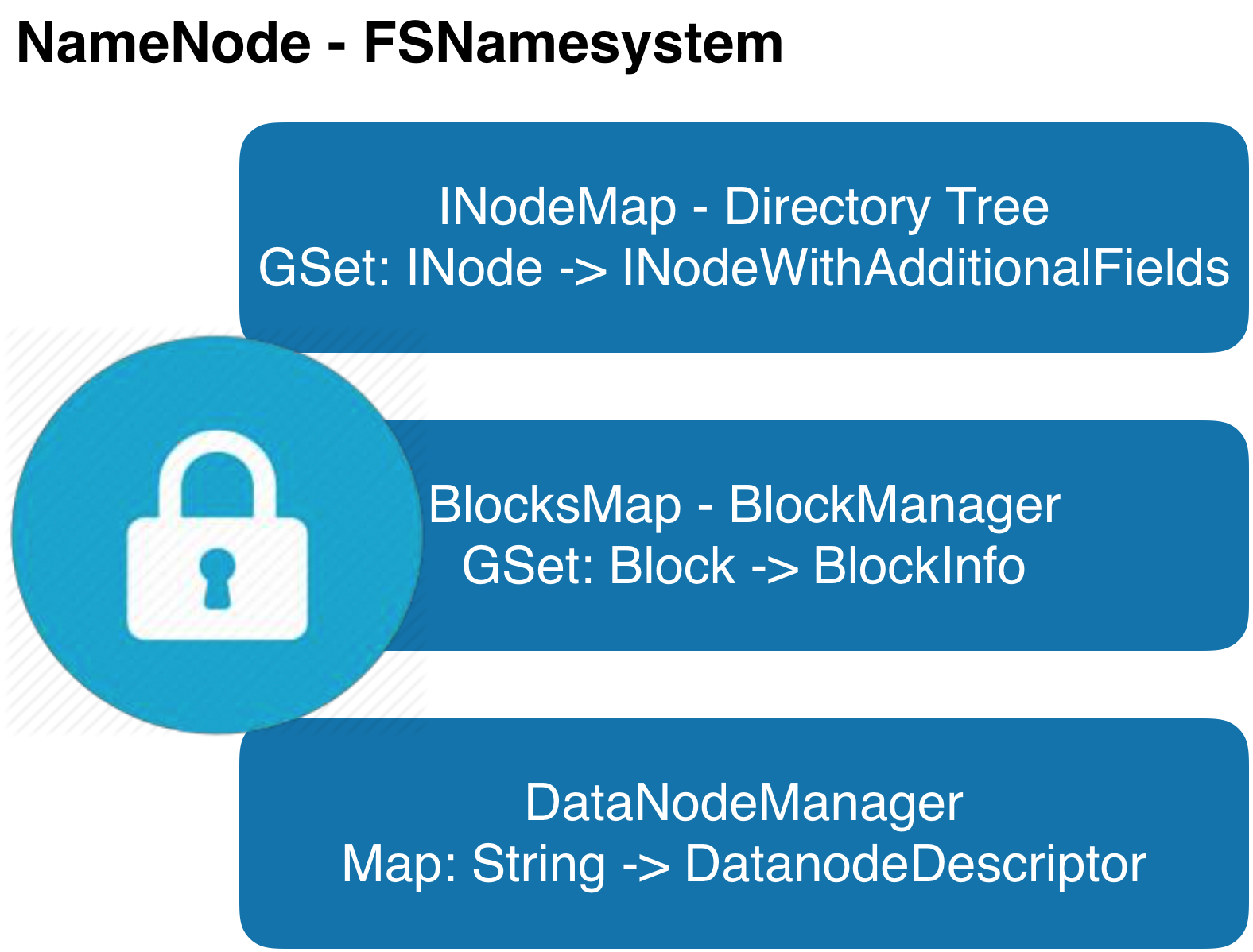
为了更好地理解使用全局锁存在的问题,首先梳理全局锁管理的主要数据结构,大致分成三类:
(1)目录树:文件系统的全局目录视图。获取目录树上任一节点的信息必须先拿到全局读锁;目录树上任一节点新增、删除、修改都必须先拿到全局写锁。
(2)数据块集合:文件系统的全量数据信息。获取其中任一数据块信息必须先拿到全局读锁;新增、删除,修改都必须先拿到全局写锁。
(3)集群信息:HDFS集群节点信息的集合。获取节点信息等必须先拿到全局读锁;注册,下线或者变更节点信息请求处理时必须先拿到全局写锁。当然为了减少对全局影响,后续版本里少数如生命线等RPC请求不再获取全局锁,部分不适合使用全局锁的处理逻辑,将并发控制下放到具体的节点信息,尝试提升处理能力。
具体实现上,NameNode使用了JDK提供的可重入读写锁(ReentrantReadWriteLock),我们知道ReentrantReadWriteLock对并行请求有严格限制,简单来说:读锁并行写锁排它。
针对不同RPC请求的处理逻辑,按照需要获取锁粒度,我们可以把所有请求抽象为读(Read Handler,获取全局读锁)和写(Write Handler,获取全局写锁)两类。
Read Handler:客户端请求(getListing/getBlockLocations/getFileInfo)、服务管理接口(monitorHealth/getServiceStatus)和主从节点之间请求(getTransactionID)等;
Write Handler:客户端请求(create/mkdir/rename/append/truncate/complete/recoverLease)、服务管理接口(transitionToActive/transitionToStandby/setSafeMode)和主从节点之间请求(rollEditLog)等;
这里只列了一些常用请求类型,其他如Cache/Snapshot/ACL/XAttr/Quota/Lease及NameNode内部线程调用等需要获取锁的逻辑没有再详细列出和归类。

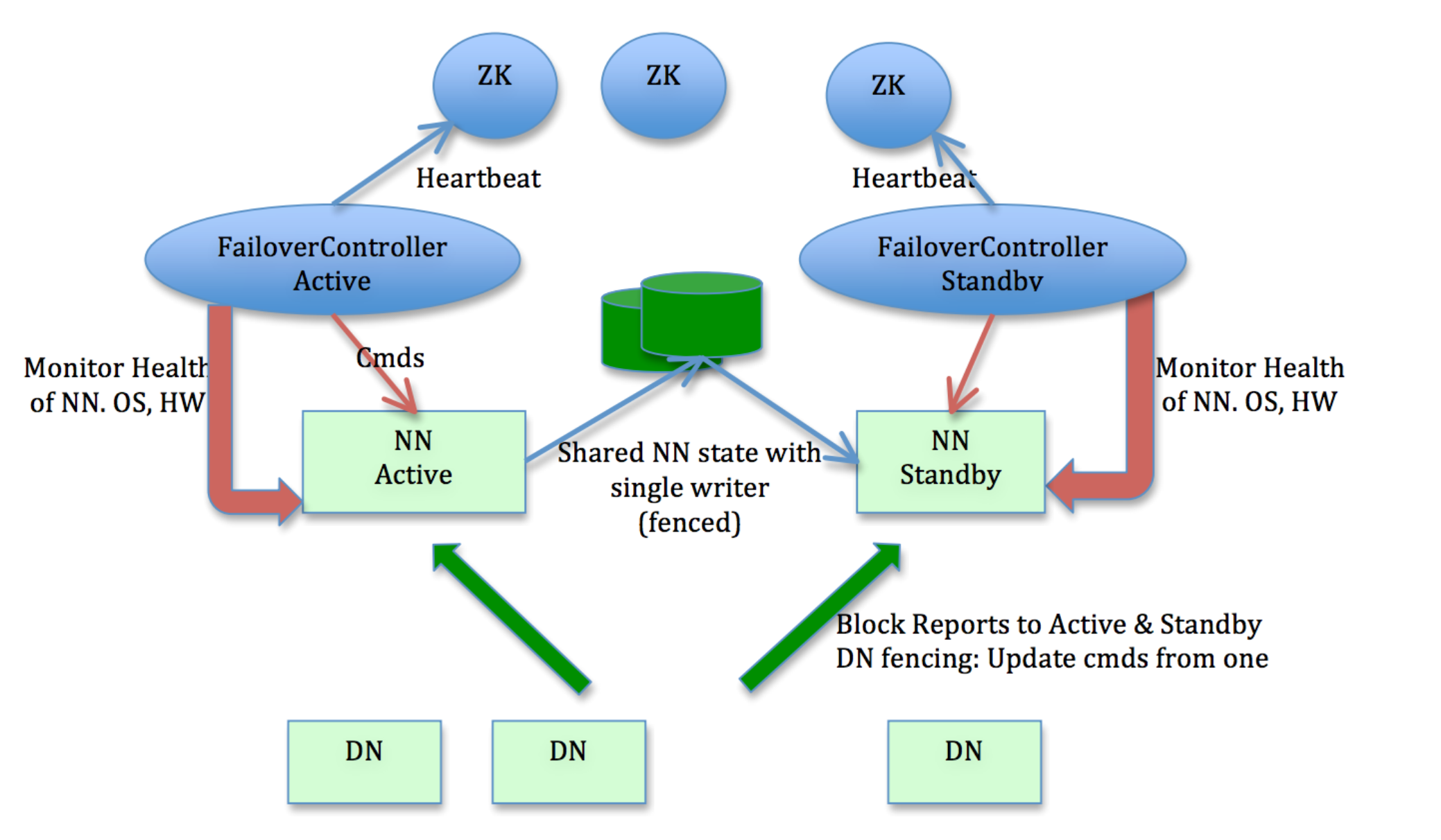
NameNode的锁控制如图3所示。核心处理逻辑路径上有两把锁:FSNamesystemLock和FSEditLogLock。其中FSNamesystemLock即为通常所说的全局锁,采用ReentrantReadWriteLock机制实现;另外为了实现高可靠/高可用的目的,NameNode需要将对部分元数据的修改实时同步到EditLog,为了提升性能,EditLog读写不在FSNamesystemLock锁内执行,独立维护锁控制并行读写,暂称为FSEditLogLock,采用Synchronized排它机制实现。
(1)获取全局锁(FSNamesystemLock)入口:外部RPC请求从IPC层进入NameNode和内部线程请求;
(2)获取局部锁(FSEditLogLock)入口:主要来源外部RPC请求对元数据的写操作;
以RPC请求#mkdir为例:
(1)RPC请求从IPC层进入NameNode;
(2)获取全局写锁(FSNamesystemLock#writeLock#lock),如果持有读锁或者写锁的请求正在被处理,排队等待;
(3)更新内存目录树结构;
(4)释放全局写锁(FSNamesystemLock#writeLock#unlock);
(5)获取EditLog排它锁;
(6)写EditLog;
(7)释放EditLog排它锁;
(8)通过IPC层将结果返回客户端;
可以看到,单个RPC请求处理流程经过了两次获取锁阶段。虽然二者相互独立,但其中任意一处如果不能及时获取到锁,RPC将处于排队等待状态,直到成功获得锁。等锁时间直接影响请求响应性能,极端场景下如果长时间不能获得锁,将造成IPC队列堆积,TCP连接队列被打满,客户端出现请求超时或者失败重试,新建连接超时失败等各种异常问题。
另外从全局来看,写锁因为排它对性能影响更加明显。如图3所示,如果当前有写请求正在被处理,其他所有请求都必须排队等待,直到写请求被处理完成释放锁后再竞争全局锁。
通常情况下,FSNamesystemLock锁范围要远大于FSEditLogLock锁范围。考虑负载较高的大规模集群,按照9:1读写比预估,只有10%请求需要同时获取FSNamesystemLock和FSEditLogLock,但是100%请求需要获取全局锁FSNamesystemLock。再加上新型硬件(SSD/3DPoint/PM)对IO性能的支持,EditLog写入性能远高于实际需求。所以从整体上看,当集群规模增加和负载增高后,全局锁FSNamesystemLock将逐渐成为NameNode性能瓶颈。如果能彻底解决NameNode全局锁问题,HDFS性能将得到极大提升。
三、拆锁复杂度
如前述,NameNode全局锁的拆分能带来非常可观的收益,Hadoop社区和业界也尝试过多次,但是从结果来看,效果都不理想。就我个人理解,其中问题复杂度客观存在,当然也有一些主观因素。总结下来有几个方面:
1、问题复杂度
Hadoop发展到今天已经超过十年,其中HDFS经过多次迭代演进,架构已经非常复杂。图4所示为HDFS项目包含和依赖的不完全组件列表,即使从事HDFS开发和运维的专业人员,想要完整了解和掌握HDFS的所有组件绝非易事。

仅针对NameNode组件,架构上模块划分不够清晰,内部核心数据结构和工作线程之间耦合非常严重。比如:
(1)INodeFile通过对象引用关联Block,这种引用关系存在天然的耦合,很难通过不同锁进行并发访问控制;
(2)数据块写入完成后除了直接更新Block状态外,还需要再次回去更新文件属性,比如存储空间占用;
(3)在可靠性上使用到的FSImage和FSEditLog两份持久化数据内Namespace和BlocksMap数据共存;
实现细节上,还存在大量相互依赖,不一而足。
除了问题本身的复杂度,工程复杂度也比较高,据不完全统计,trunk分支上仅HDFS项目代码量超过1000K LOC,其中非测试代码量超过760K LOC,包括了超过2000类文件,要想优雅实现锁粒度拆分工程量很大。
2、实际需求
以社区版本branch-2.7为例,经过性能优化,NameNode处理能力可以达到5000TPS(写请求)或200000QPS(读请求),这种处理能力能够满足大多数公司的实际需求。如果负载超过这个量级一般也能通过Federation架构做横向扩展解决(虽然Federation架构在使用上会遇到很多意想不到的问题)。真正有实际需求,并需要尝试降低NameNode全局锁粒度解决性能问题的场景并不多。
NOTE:性能数据是具体场景读写比例压测结果,不具备通用性,请谨慎参考。
3、社区动力不足
社区在全局锁和扩展性问题上做过多次尝试。比较有代表性的几类工作如下:
HDFS-8966:Separate the lock used in namespace and block management layer
HDFS-5453:Support fine grain locking in FSNamesystem
HDFS-8286:Scaling out the namespace using KV store
HDFS-7836:BlockManager Scalability Improvements
几类方案中都描述了非常好的愿景,但是这些工作多数只推进了其中一部分,有的甚至还处于方案讨论阶段。总之,从几次尝试工作的结果来看,社区在这个方向上的动力并不足,投入有限。
4、历史问题
HDFS最初设计时为了实现简单方便做了很多取舍,其中全局锁是对后续的发展影响较大的一个。之后架构迭代中,大量工程实现都在全局锁基础上构建,确实对开发工作有很多便捷,但是如果想尝试梳理清楚和优雅拆分难度较大。
四、拆锁讨论
事实上,在分布式文件系统中,为实现解决数据一致性,通常都会不可避免遇到锁问题。不同的是,对于适合不同场景的文件系统,做的妥协或采用的方法有很大差异。借鉴成熟文件系统的锁模型,可以为HDFS拆锁工作提供一些参考和借鉴。其中Alluxio是非常好的参考对象,本章在调研Alluxio锁模型基础上,分析降低NameNode全局锁粒度的可能发展方向。
4.1 Alluxio内存锁模型
Alluxio[2]是一个基于内存的分布式文件系统,得益于云计算场景下的良好表现,被广泛部署和应用。
同HDFS类似,Alluxio也使用了Master-Slave的架构,其中Master管理Alluxio集群所有的元数据,包括目录树结构、数据块集合和分布及集群节点信息。实现上,FileSystemMaster负责管理整个目录树,BlockMaster管理数据块集合和分布,集群节点信息由BlockMaster中单独的集合数据结构mWorkers独立管理。
整体框架上与HDFS非常相似,但是具体到实现上,差异比较明显。
(1)FileSystemMaster和BlockMaster完全独立,通过blockid关联;
(2)mWorkers与FileSystemMaster/BlockMaster之间不存在复杂的耦合关系;
为了实现数据一致性,FileSystemMaster/BlockMaster/mWorkers之间独立加锁,以达到最好的并行性能。具体来看:
1、FileSystemMaster中目录树上所有节点各自维护读写锁(ReentrantReadWriteLock),控制并发读写:
(1)一元操作符:按照路径从根目录开始顺序加锁,写锁只加到最后一级目录,其他目录均加读锁;
(2)二元操作符:对公共目录非最后一级加读锁,最后一级根据操作符加读/写锁,剩余目录按照最后一级公共目录顺序加锁。
(3)为避免死锁,对于二元或者多元操作符先按路径排序,根据排序结果顺序对路径分别加锁;

2、BlockMaster完全独立于FileSystemMaster,核心数据结构mBlocks使用ConcurrentHashMap控制并发读写,具体到单个Block操作使用synchronized控制;
3、mWorker本身使用线程安全的集合数据结构管理,涉及到注册心跳等操作时,为每一个worker独立加锁;
从整个锁逻辑上看,有几点非常值得借鉴的地方:
(1)所有模块之间耦合度极低,核心逻辑不存在排它锁影响性能;
(2)为了将锁影响控制到最低,使用了大量在具体对象(block/worker)上加锁逻辑,而不是全局;
当然,凡是都有利弊,降低锁冲突提升性能一定是需要付出代价的:
(1)内存开销,因为在FileSystemMaster中目录树所有节点上独立使用读写锁(ReentrantReadWriteLock),会存在大量的内存对象的开销,制约Alluxio集群规模;在64bit环境上统计数据结构ReentrantReadWriteLock的footprint:
1 2 3 4 5 6 7 8 | |
对于一个10亿节点的目录树,仅ReentrantReadWriteLock对象的内存开销就将到~120GB,显然是一个巨大的开销。
(2)Alluxio的Master节点为了实现高可用,本身采用集群方式部署,为了保证一致性,所有元数据必须同步。这里涉及到FileSystemMaster/BlockMaster的Journal独立持久化逻辑,Alluxio实现时,将这部分逻辑都放在了锁内,对写请求处理的性能影响较大。
4.2 GFS锁模型
重新回顾GFS1.0是如何管理目录树和目录锁。下面是从论文《The Google File System》[4]中摘抄的有关目录树和锁机制的描述段落。
Many master operations can take a long time: for example, a snapshot operation has to revoke chunkserver leases on all chunks covered by the snapshot. We do not want to delay other master operations while they are running. Therefore, we allow multiple operations to be active and use locks over regions of the namespace to ensure proper serialization. Unlike many traditional file systems, GFS does not have a per-directory data structure that lists all the files in that directory. Nor does it support aliases for the same file or directory (i.e, hard or symbolic links in Unix terms). GFS logically represents its namespace as a lookup table mapping full pathnames to metadata. With prefix compression, this table can be efficiently represented in memory. Each node in the namespace tree (either an absolute file name or an absolute directory name) has an associated read-write lock. Each master operation acquires a set of locks before it runs. Typically, if it involves /d1/d2/…/dn/leaf, it will acquire read-locks on the directory names /d1, /d1/d2, …, /d1/d2/…/dn, and either a read lock or a write lock on the full pathname /d1/d2/…/dn/leaf. Note that leaf may be a file or directory depending on the operation. We now illustrate how this locking mechanism can prevent a file /home/user/foo from being created while /home/user is being snapshotted to /save/user. The snapshot operation acquires read locks on /home and /save, and write locks on /home/user and /save/user. The file creation acquires read locks on /home and /home/user, and a write lock on /home/user/foo. The two operations will be serialized properly because they try to obtain conflicting locks on /home/user. File creation does not require a write lock on the parent directory because there is no “directory”, or inode-like, data structure to be protected from modification. The read lock on the name is sufficient to protect the parent directory from deletion. One nice property of this locking scheme is that it allows concurrent mutations in the same directory. For example, multiple file creations can be executed concurrently in the same directory: each acquires a read lock on the directory name and a write lock on the file name. The read lock on the directory name suffices to prevent the directory from being deleted, renamed, or snapshotted. The write locks on file names serialize attempts to create a file with the same name twice. Since the namespace can have many nodes, read-write lock objects are allocated lazily and deleted once they are not in use. Also, locks are acquired in a consistent total order to prevent deadlock: they are first ordered by level in the namespace tree and lexicographically within the same level.
从这段描述里我们可以看到GFS对锁的管理:
(1)目录树中节点各自独立管理锁来控制并发;
(2)对锁模型更加激进,比如创建文件在整条路径上只使用读锁;
(3)为了避免死锁,对多元操作符按照路径排序后顺序加锁;
整体来看,Alluxion目录树锁机制与GFS锁机制异曲同工,将并行处理能力最大化。
4.3 HDFS拆锁讨论
借鉴和参考前面两类文件系统锁机制实现并结合HDFS现状,我个人认为HDFS降低全局锁粒度的可能发展路线:
1、垂直拆分[3]
NameNode内存几个核心数据结构里,DataNodeManager管理的内容相对独立,比较容易独立拆分出去,事实上社区现在基本完成了这个工作,下面只考虑两个核心数据结构Namespace和BlocksMap:
(1)按照HDFS Federation架构的思路,在单NameNode进程内实施Federation;
(2)将Namespace按照Range进行垂直切分;
(3)Namespace变化成两级管理结构;
1 2 | |
(4)Range内独享锁,Range之间可并行访问;
(5)跨Range多元操作符按照Range排序后顺序加锁避免死锁;
(6)当单进程整体负载较高时,Range重新分配独立进程,实现动态切分目录树的效果;
目录树的垂直切分思路到最后可以跟HDFS Federation很好的结合起来(虽然HDFS Federation架构存在很多问题)实现类似Ceph中简化版Dynamic Subtree Partitioning目标。
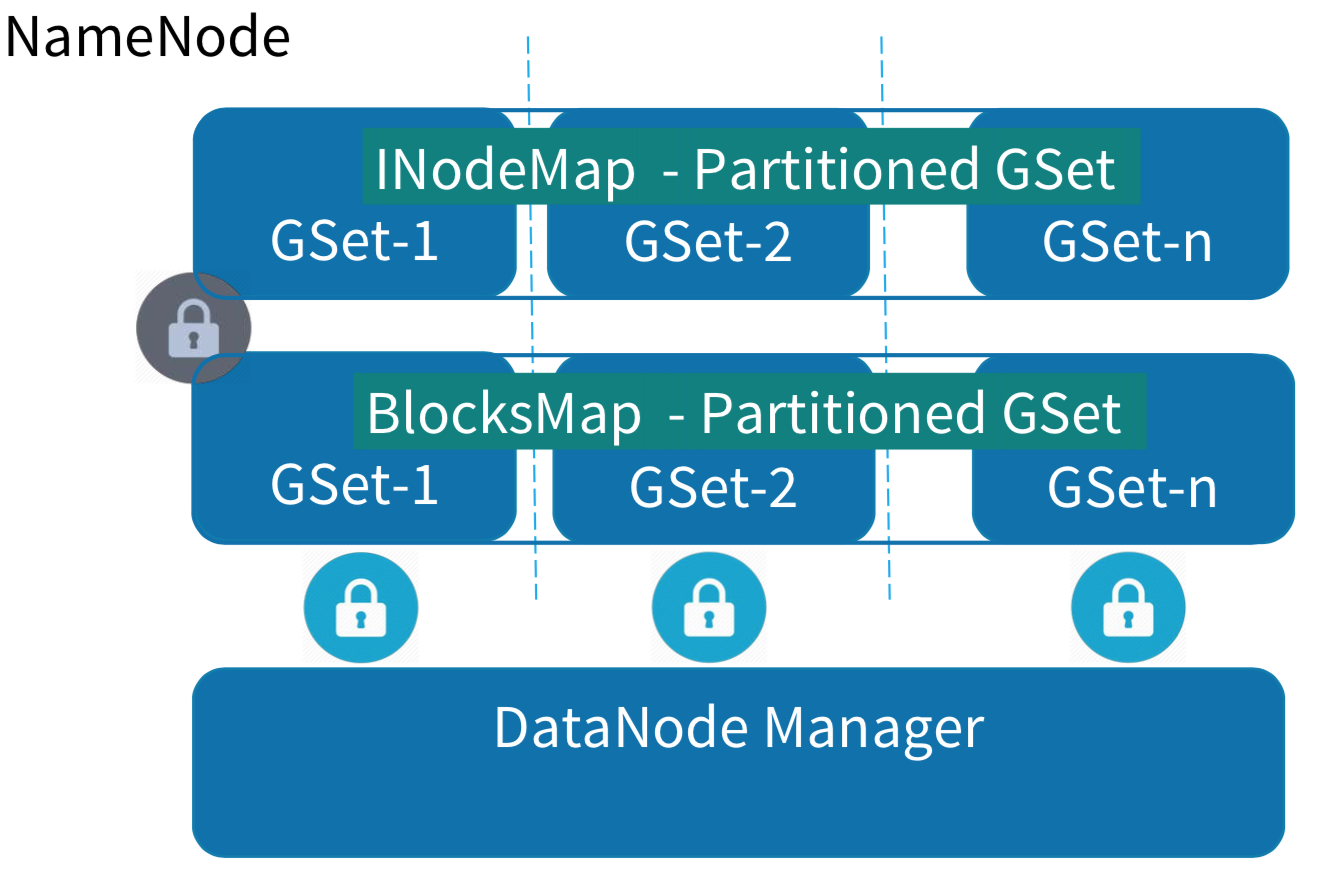
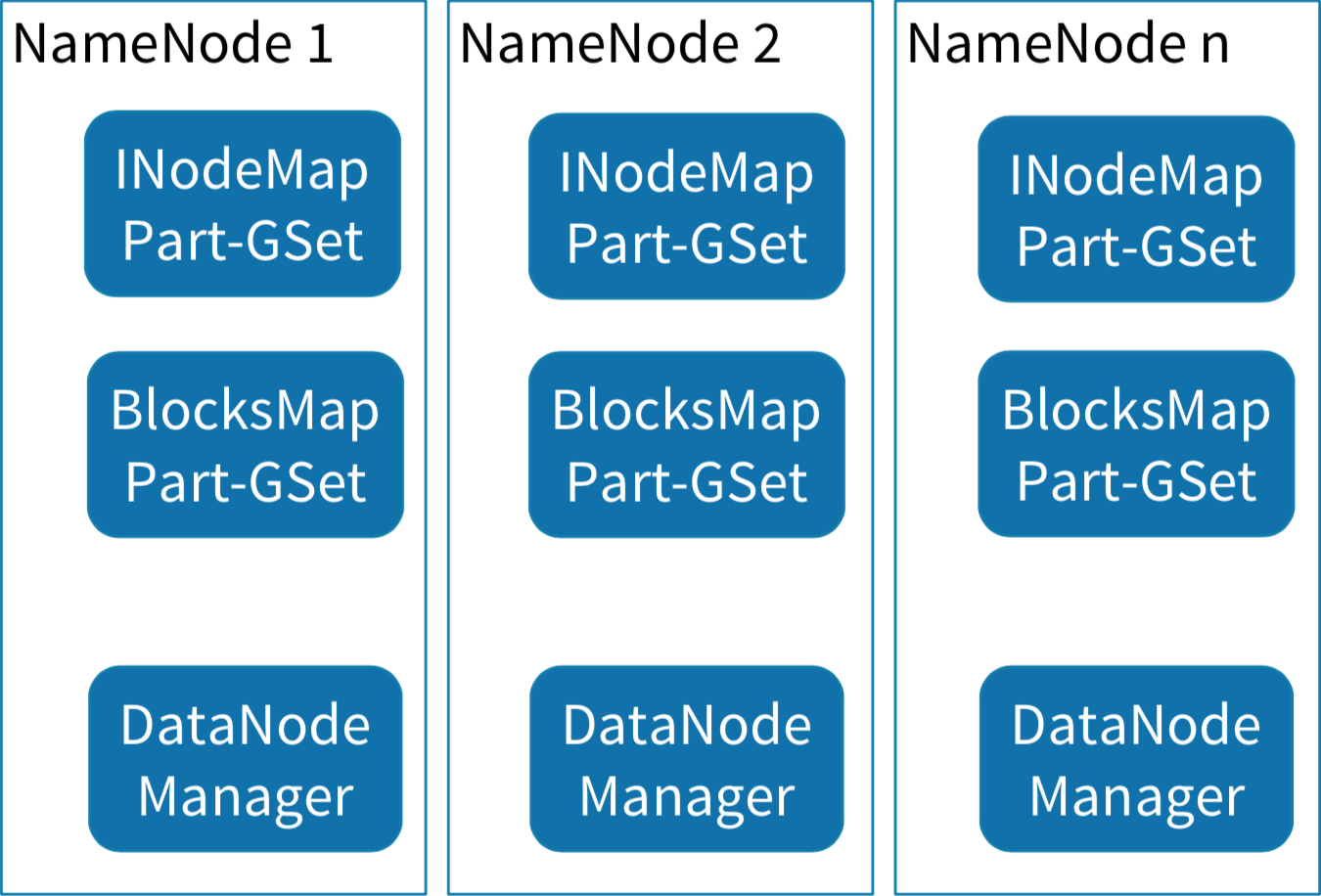
2、水平拆分
NameNode全局锁水平拆分的思路可以借鉴GFS1.0和Alluxio解决思路,按照两个阶段降低NameNode锁粒度:
第一阶段:对NameNode核心数据结构进行分层解耦,不同层独立持锁;
第二阶段:降低Namespace层锁粒度;
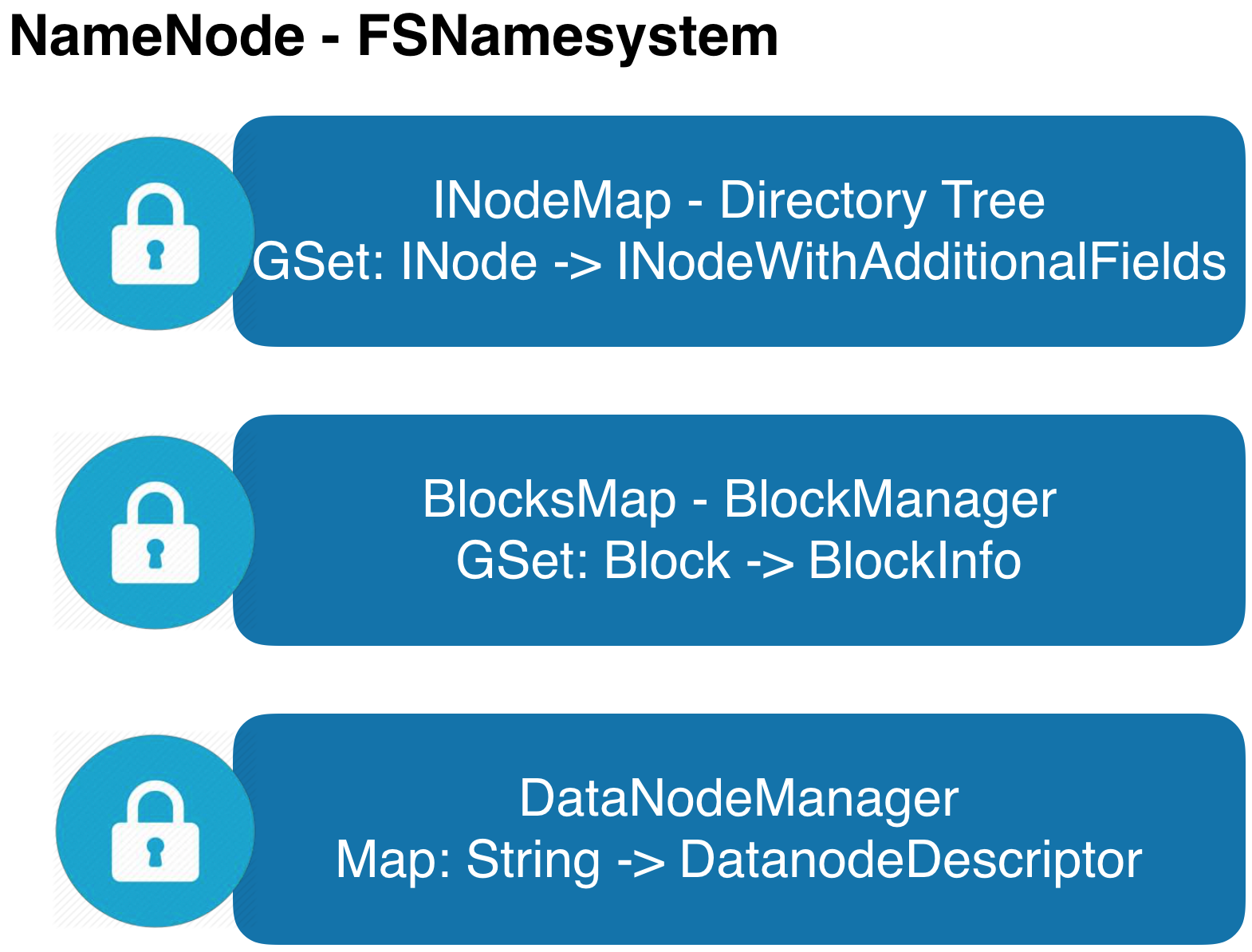
第一阶段分层解耦:
(1)Namespace层维护与目录树有关的所有数据结构(INodeMap,Lease等),核心是INodeMap,目录树文件节点上通过List
(2)BlocksManager层维护与数据块相关的所有数据结构(BlocksMap,ReplicationMonitor,NetworkTopology等),核心是BlocksMap:GSet<BlockId, BlockInfo>;将副本数和存储策略等与数据块有关的属性统一下沉到BlockInfo内,降低Namespace与BlocksManager的耦合;(一部分工作社区已经完成)
(3)DataNodeManager层仅维护集群节点数据结构,不维护拓扑结构(非重点,当前的实现已经不在锁内);
(4)每一层维护独立锁,开放接口以线程安全方式对外暴露。
拆分后同一进程内会出现多把独立锁,不可避免会存在锁内相互调用的问题,为了避免出现死锁,可以做简单约束:
(1)单次请求处理涉及数据结构
(2)尽可能减少或避免锁内跨层调用(如Alluxio);
(3)特殊场景需要锁内跨层调用时,仅允许Namespace到BlocksMap单向调用;
第二阶段降低锁粒度:
(1)目录树全局锁下沉到目录树节点,不过如前述因为ReentrantReadWriteLock的footprint较大,直接使用容易造成内存瓶颈。可以选择以下优化和改进:
* 按照满足读写锁能力的最小资源重新实现Lock,降低整颗目录树节点使用锁后的内存占用;
* 维护独立的目录锁动态子树;因为NameNode进程内提供的请求处理线程数有限,目录锁子树规模非常小,几乎没有管理和遍历的成本;
(2)写锁仅持有写操作的最后一级目录,其他父目录均加读锁;
(3)多元操作符按照请求目录排序后顺序加锁避免死锁;

全局操作类型,比如safemode/haadmin/metasave因为都是superuser类请求,频率非常低,不需要再维护独立锁。为了简化,对大部分superuser管理类型的请求可以同时获取两把写锁,对整体性能不会有影响。
五、总结
NameNode全局锁一直是影响HDFS性能的关键问题,尽管社区在这方面做过多次尝试,但是结果都不是很理想。其中的问题难度客观存在。
(1)HDFS架构快速迭代和演进,丰富的功能和更加复杂组件让HDFS内部模块之间存在千丝万缕的耦合关系,完全梳理清楚成本较高;
(2)HDFS项目代码量除单元测试外接近780K LOC,工程量很大;
(3)设计之初为实现简单做了很多取舍,比如全局锁及在此基础上的大量工程实现(“战术的勤奋掩盖战略的懒惰”的实例);
虽有难度但也存在办法,本文在参考其他分布式文件系统锁模型的基础上,结合当前HDFS实际情况和业界正在尝试的方向,期望提供两种降低全局锁粒度的思路和可能演进方向,两种演进方向相互没有依赖,可以并行演进。
当然,提升性能或者扩展能力,拆分NameNode全局锁并不是唯一解。比如由LinkedIn和Hortorworks分别在推进的Observer NameNode和OZone都是非常好的思路。
Observer NameNode通过开放Standby读能力提升NameNode整体QPS。
Hadoop OZone通过引入对象存储思路,将文件系统的元数据进行分解下沉,期望能够实现良好的性能和扩展能力。
六、参考
[1] https://hadoop.apache.org/docs/r3.2.0/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
[2] https://www.alluxio.org/
[3] https://engineering.linkedin.com/blog/2019/02/the-present-and-future-of-apache-hadoop--a-community-meetup-at-l
[4] https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf