一、背景
HDFS NameNode重启效率是另一个被长期诟病的问题,尤其对超大规模集群,动辄数小时的重启时间对整个集群的稳定性和可用性都存在极大的潜在风险,HDFS NameNode重启优化一文对NameNode启动效率提升的优化办法做过简单梳理和探讨,但是从实践情况来看,虽然有提升,但是依然存在优化空间。
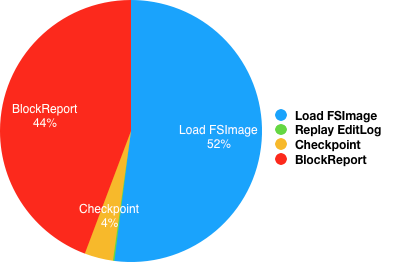
从线上一组NameNode重启的抽样数据为例来看,整个重启时间依然非常可观,具体到重启每阶段的时间分布如图1所示(时间占比分布情况受元数据量、NameNode本地存储介质和集群规模等诸多因素影响,不具备一般性,仅供参考)。从时间分布来看,占比较大的是加载FSImage和BlockReport两个阶段,其中FSImage加载的实际时间开销超过小时。所以优化和提升FSImage加载效率对整个进程重启有很大帮助。
本文将在介绍FSImage原有加载方式基础上,分析效率低的原因,并结合加载方式的演进和实践效果对FSImage的并行加载优化进行简单说明,期望能有借鉴和参考价值。
二、重启流程
在HDFS的整个运行期里,整个文件系统的目录树均在NameNode内存中集中管理,但由于内存易失特性,一旦出现进程退出、宕机等异常情况,所有元数据都会丢失,将给整个系统的数据安全会造成不可恢复的灾难。为了更好的容错能力,NameNode(SBN/Secondary)会周期进行Checkpoint,将文件系统的目录树持久化到外部设备,即二进制文件FSImage,这样即使NameNode出现异常也能从持久化设备上恢复元数据,保证了数据的安全可靠。详细分析参考HDFS NameNode重启优化一文。
在HA with QJM架构下,NameNode重启始终以SBN(StandbyNameNode)角色开始。启动过程大致分成以下几个阶段:
0、加载FSImage:从最新持久化的FSImage中恢复文件系统的目录树结构;
1、回放EditLog:通过回放EditLog对齐最新的目录树结构;
2、执行Checkpoint:可选操作;
3、收集所有DataNode的注册和数据块汇报:重建文件的数据块内容具体分布;
FSImage完整记录了文件系统目录树相关的数据。从Hadoop-2.4.0起,FSImage开始使用Google Protocol Buffers编码格式描述(HDFS-5698),详细描述文件见fsimage.proto,当然在后续的版本中也有调整,但整体上没有本质差异。根据描述文件和实现逻辑,FSImage文件组织格式如图2所示。

从fsimage.proto和FSImage文件存储格式容易看到,除了文件头部校验(MAGIC)和尾部文件索引(FILESUMMARY)等管理信息外,核心数据都是与文件系统目录树强相关。其中INODE和INODE_DIR是整个FSImage文件中最核心且也是规模最大的两个部分。
NameNode重启的第一个步骤就是加载FSImage,传统的加载完全按照串行方式执行:
(1)FSImage文件MD5值校验;
(2)读取FSImage文件的Summary数据;
(3)根据Summary的信息对每个Section依次读取、反序列化并构建内存数据结构;
其中两个规模最大的两个Section即INODE和INODE_DIR。假设针对包含1亿个INode目录树的加载过程:需要先将1亿个INode从FSImage文件中按序读入并反序列化;完成后再将包含1亿条父子关系的INODE_DIR按序读入并反序列化,根据反序列化结果将所有子节点的引用按照二分查找的方式插入到父节点维护的数组中,到这里基本上目录树就构建起来(当然如果开启了如SNAPSHOT和Cache等特性的话,还需要将这部分数据加载完成),目录树构建完成后的内存组织情况详情参考NameNode内存全景。
使用传统的FSImage加载模式,测试验证~3亿节点规模的目录树,FSImage文件大小~30GB,加载过程时间开销统计:
- MD5校验耗时~125sec;
- FSImage加载时间~811sec;
三、并行加载优化
如果分析FSImage的整个加载过程,尤其是占比最大的INODE和INODE_DIR两个Section容易发现两个特点:
(1)INODE_DIR加载依赖INODE完成,即INODE和INODE_DIR两个Section之间存在严格的先后顺序;
(2)INODE和INODE_DIR两个Section内部Entry(目录树节点数据和节点之间父子关系信息)相互之间其实完全独立;
根据这两个特点,我们可以把INODE和INODE_DIR内部结构进一步做逻辑拆分,切割成多个INODE_SUB和多个INODE_DIR_SUB便于后续并行处理,其中:
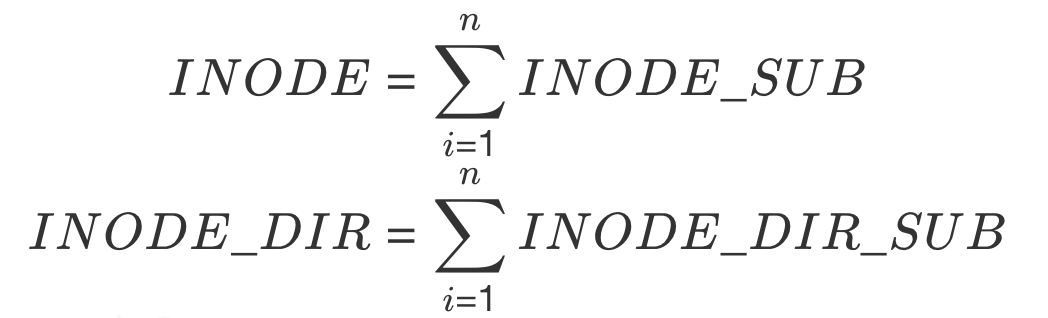
将INODE和INODE_DIR两个Section进行逻辑拆分后其实不影响FSImage物理上的组织结构。为了能把INODE_SUB和INODE_DIR_SUB真正的分配给独立的线程且不重不漏,只需要在FSImage文件的FILESUMMARY索引里对逻辑SUB_SECTION(INODE_SUB+INODE_DIR_SUB)做好记录:偏移量+长度。

FSImage文件索引数据就绪后,当再次重启触发加载时,根据SUB_SECTION的个数及配置的加载线程数进行均衡拆分:
(1)确保多个线程之间分配到的SUB_SECTION尽可能相同;
(2)每一个SUB_SECTION只被一个线程独立消费;
通过这种方式拆分,FSImage的加载过程可以演变成如下图4所示流程。

从整个优化思路可以看到,FSImage文件物理结构没有大调整,仅对FILESUMMARY做了简单扩展,核心数据组织上没有做任何改变,所以兼容能力上相对更好。
(1)使用原有逻辑加载新格式的FSImage文件时仅需要在读取FILESUMMARY时将INODE_SUB和INODE_DIR_SUB两类SECTION的索引过滤掉就可以,事实上在实现时也是这么处理的,即使是较早版本的实现也非常容易修复;
(2)并行逻辑加载原有格式FSImage文件时因为在FILESUMMARY中没有SUB_SECTION描述,所以及时升级到并行加载逻辑在真正执行时也是单线程完成;
整体上看,这种并行加载方案在效率和兼容性上能做到兼顾。
四、其他优化
除了对INODE和INODE_DIR并行加载优化外,其实社区参与者还提出了其他实现逻辑的优化,其中效果较好的主要有:
(1)异步MD5检查;
在图4的FSImage加载流程里,为了检查FSImage文件合法性,第一步需要对其进行MD5校验。这个步骤需要执行一次完整的FSImage文件读操作,如果文件较大,IO开销比较可观。为了提升加载效率,HDFS-13694提出将MD5检查逻辑从主流程中摘出来,用独立的线程异步执行检查,减少文件合法性检查引入的时间开销。
(2)加载INODE_DIR/INODE_DIR_SUB去掉二分查找逻辑;
如前述,INODE_DIR Section实际上是为了构建目录树节点之间的父子关系。为了提升检索效率,父节点使用数组按照字符序维护子节点引用的集合,这样处理后读取时容易通过二分查找的方式在O(logn)时间复杂度内就完成检索;为了满足子节点有序的条件,传统方式当加载INODE_DIR/INODE_DIR_SUB时也是先按照二分查找的方法定位到每一个子节点引用应该插入到数组的具体位置,再执行插入操作。但事实上,对目录树序列化操作时(即执行Checkpoint)子节点本身都已经是有序持久化到FSImage的INODE_DIR Section内,所以加载的时候每一次二分查找的目标位置一定是数组尾部。这种情况下其实二分查找定位目标位置的逻辑完全没有必要。HDFS-13693提出按照INODE_DIR内Entry的加载顺序逐个插入子节点数组的尾部,去掉二分查找逻辑。
五、效果验证
测试环境
1、基础环境:
CPU: Intel® Xeon® CPU 2.60GHz
OS: CentOS 6.6
FS: EXT4 on HDD
JDK: Java HotSpot™ 64-Bit Server VM 1.8.0
2、数据规模:
INode总数:~3亿
Block数:~3亿
FSImage大小:~30GB
3、测试场景:
原生加载
并行加载(默认线程数12)
并行加载+异步MD5校验
并行加载+异步MD5校验+跳过二分查找
结果对比
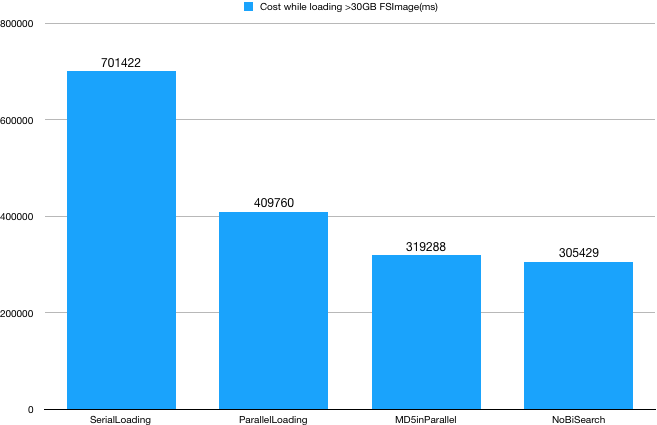
下图5是针对同一份元数据使用不同策略执行加载过程耗时情况。
结果说明:
(1)将INODE和INODE_DIR两个最大规模的元数据并行化加载收益最明显,使用12个线程数加载效率有~40%的提升;实际场景中具体应该使用多少线程执行并行加载需要综合考虑服务器核数和元数据规模等。
(2)MD5检查是容易被忽略的部分,尤其针对较大规模元数据场景,因为需要一次完整IO过程,所以开销也比较可观~10%;这里的主要开销在IO,所以与FSImage文件大小强相关。
(3)虽然在加载INODE_DIR构建节点之间父子关系时可以跳过二分查找,直接进入数组尾部,但是效果并不明显。原因在于:一般场景子节点的规模都不大,另外二分查找本身的开销非常低;在常规服务器上即使对1亿规模的数据执行1亿次二分查找的耗时不超过10秒;
使用参数
FSImage并行加载特性使用的主要参数如下:
1、dfs.image.parallel.load: 描述是否开启并行加载特性;
2、dfs.image.parallel.target.sections: 描述开启并行加载特性后新生成的FSImage里包含的SUB_SECTION个数,一般建议设置为dfs.image.parallel.threads的整数倍;
3、dfs.image.parallel.inode.threshold: 描述开启并行加载特性所需节点数的最小阈值,对小规模元数据并行加载并不会有很好的效果,所以默认在1000000节点规模下,并行加载特性不会开启;
4、dfs.image.parallel.threads: 描述并行加载使用的线程数,需要综合考虑元数据规模和NameNode进程所在服务器的承载能力适当调整。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | |
社区在优化和解决FSImage加载问题的讨论持续了较长时间,其中比较典型的解决方案还有如HDFS-7784和HDFS-13700等,这些解决方案虽然没有最终合入主干代码,但是都提供了非常不错的想法。综合考虑性能、稳定性和兼容能力,HDFS-14617优势明显,另外从实践效果上看HDFS-14617也有较好的表现。如果集群规模和元数据规模较大,且重启加载FSImage阶段耗时严重,并行加载特性值得一试。
六、参考
[1] https://issues.apache.org/jira/browse/HDFS-14617
[2] https://issues.apache.org/jira/browse/HDFS-13694
[3] https://issues.apache.org/jira/browse/HDFS-13693