一、背景
NameNode内存数据主要对整个文件系统元数据的管理。Namenode目前元数据管理可以分成两个层次,一个是Namespace的管理层,这一层负责管理HDFS分布式文件系统中的树状目录和文件结构;另一层则为Block管理层,这一层负责管理HDFS分布式文件系统中存储文件到物理块之间的映射关系BlocksMap元数据。其中对Namespace的管理数据除在内存常驻外,会定期Flush到持久化设备中;对BlocksMap元数据的管理只存在内存;当NameNode发生重启,需要从持久化设备中读取Namespace管理数据,并重新构造BlocksMap。这两部分数据结构占用巨大的JVM Heap空间。
除了对文件系统本身元数据的管理外,NameNode还需要维护DataNode本身的元数据,这部分空间相对固定,且占用空间较小。
从实际Hadoop集群环境历史数据看,当Namespace中包含INode(目录和文件总量)~140M,数据块数量~160M,常驻内存使用量达在~50G。随着数据规模的持续增长,内存占用接近同步线性增长。在整个HDFS服务中,NameNode的核心作用及内存数据结构的重要地位,所以分析内存使用情况对维护HDFS服务稳定性至关重要。
这里在《NameNode内存全景》基础上,进一步对NameNode内存中关键数据结构的细节进行详细解读。
二、内存分析
2.1 NetworkTopology
NameNode除对文件系统本身元数据的管理外还需要维护DataNode的信息,主要通过NetworkTopology中DatanodeDescriptor对DataNode进行表示,该类继承结构如下图示:
在整个继承机构中各个类的内存占用情况:
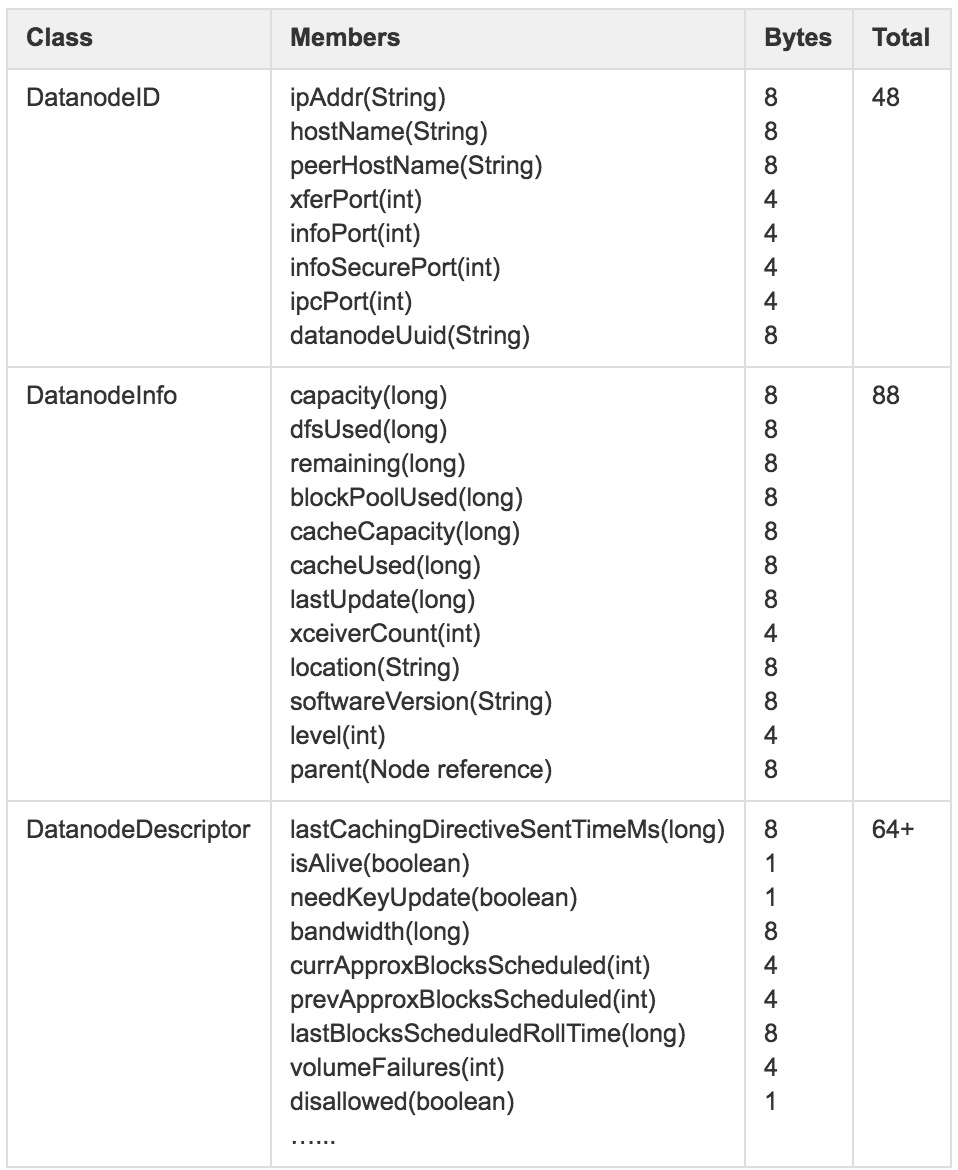
其中DatanodeDescriptor还包括一部分非常驻内存对象,这里没有详细统计,所以结果可能会有少许误差。
假设集群中包括1000个DataNode节点,仅DataNode部分占用内存情况:
(48+88+64)*1000=200000=195+K
所以仅NetworkTopology维护的DataNode信息,相比整个NameNode所占的内存空间微乎其微。
2.2 Namespace
与传统单机文件系统相似,HDFS对文件系统的目录结构也是按照树状结构维护,Namespace保存的正是目录树及每个目录/文件节点的属性,包括:名称(name),编号(id),所属用户(user),所属组(group),权限(permission),修改时间(mtime),访问时间(atime),子目录/文件(children)等信息。
下图为整个Namespace中INode的类图结构,从类图可以看出,INodeFile和INodeDirectory的继承关系。其中目录在内存中由INodeDirectory对象来表示,并用List
在整个继承关系中不同类的内存占用情况:
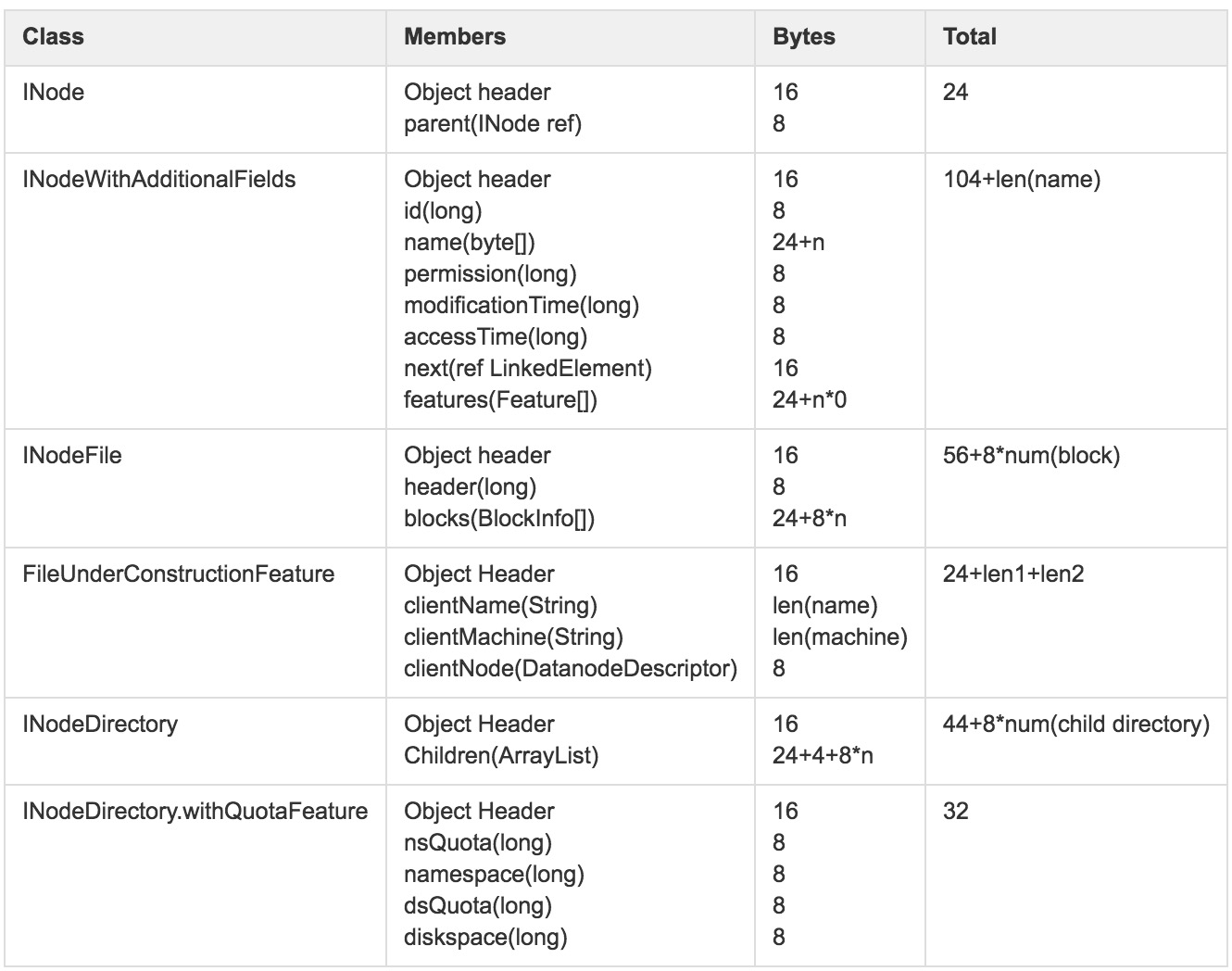
其中,除了上面提到的结构外,如目录节点的附加属性等非通用数据结构,没有在统计范围内。另外,INodeFile和INodeDirectory.withQuotaFeature在内存中使用最为广泛的两个结构。
假设Namespace包含INode数为1亿,仅Namespace占用内存情况:
(24+104+8+avg(32+44+ 8 * 2, 56+ 8 * 2)) * 100000000=21800000000=20.30GB
Namespace数据会定期持久化到外存设备上,内存也会常驻,在整个NameNode的生命周期内一直缓存在内存中,随着HDFS中存储的数据增多,文件数/目录树也会随之增加,占用内存空间也会同步增加。NameNode进程、单机内存容量及JVM对内存管理能力将成为制约HDFS的主要瓶颈。
2.3 BlocksMap
在HDFS中,每个block都对应多个副本,存储在不同的存储节点DataNode上。在NameNode元数据管理上需要维护从Block到DataNode列表的对应关系,描述每一个Block副本实际存储的物理位置,当前BlocksMap解决的即是从Block对对应DataNode列表的映射关系。
BlocksMap内部数据结构如下图示:
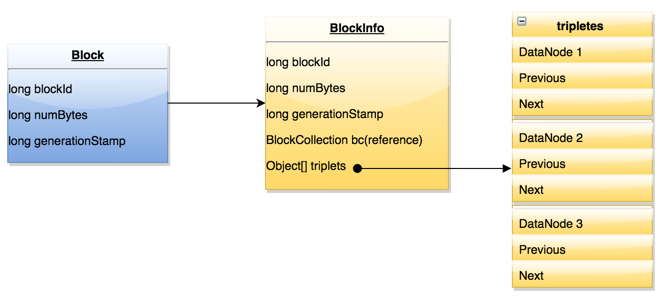
随着存储量规模不断增加,BlocksMap在内存中占用的空间会随之增加,社区在BlocksMap的数据结构使用上做过优化,最初直接使用HashMap解决从Block到BlockInfo的映射关系,之后经过优化使用重新实现的LightWeightGSet代替HashMap,该数据结构通过数据保存元素信息,利用链表解决碰撞冲突,达到更少的内存使用。
该数据结构里Block对象中只记录了blockid,blocksize和timestamp。BlockInfo继承自Block,除了Block对象中保存的信息外,最重要的是该block对应的DataNode的列表信息。
内存占用情况如下:
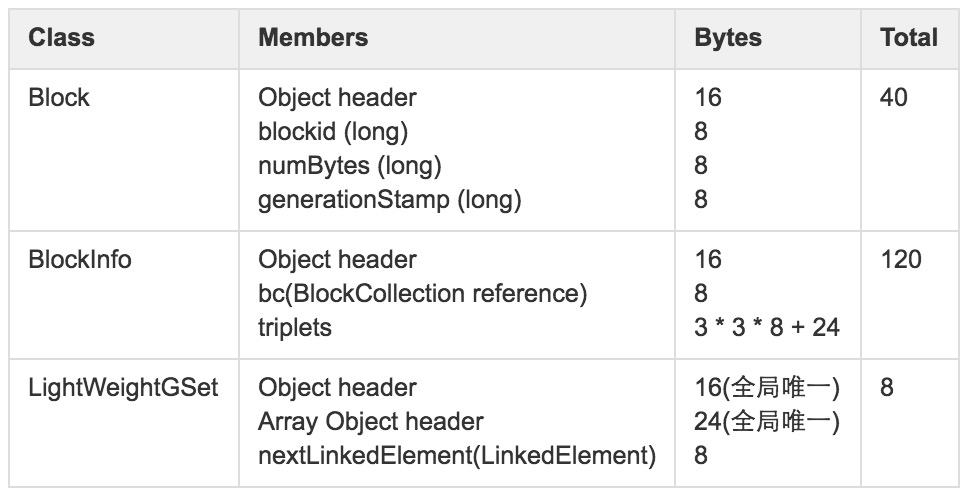
LightWeightGSet与HashMap相比,减少了HashMap在load factor避免冲突的额外内存开销,即使经过优化,BlocksMap也是占用了大量的内存空间,假设HDFS中存在1亿Block ,其占用内存情况:
(40+120+8)* 100000000=16800000000=15.65GB
BlocksMap数据常驻内存,在整个NameNode生命周期内一直缓存内存中,随着数据规模的增加,对应Namespace和Block数会随之增多,NameNode进程、单机内存容量及JVM对内存管理能力将成为主要瓶颈。
2.4 小结
根据前述对当前线上集群数据量:Namespace中包含INode(目录和文件总量):~140M,数据块数量:160M,计算内存使用情况:
Namespace:(24+104+8+avg(32+44+ 8 * 2, 56+ 8 * 2)) * 140M = ~29.0 GB
BlocksMap:(40+120+8) * 160M = ~25.0 GB
二者组合结果:29.0 GB + 25.0 GB = 53.0 GB
结果来看与监控常驻内存~50GB接近,基本符合实际情况。
从前面的讨论可以看出,在NameNode整个内存对象里,占用空间最大的两个结构即为Namespace和BlocksMap,当数据规模增加后,巨大的内存占用势必会制约NameNode进程的服务能力,尤其对JVM的内存管理会带来极大的挑战。
据了解业界在NameNode上JVM最大使用到180G,结合前面的计算可以得知,元数据总量700M基本上是服务的上限。
三、结论
1、NameNode内存使用量预估模型:Total=218 * num(INode) + 168 * num(Blocks);
2、受JVM可管理内存上限等物理因素,180G内存下,NameNode服务上限的元数据量约700M。