<property><name>dfs.image.parallel.load</name><value>true</value><description> If true, write sub-section entries to the fsimage index so it can
be loaded in parallel. Also controls whether parallel loading
will be used for an image previously created with sub-sections.
If the image contains sub-sections and this is set to false,
parallel loading will not be used.
Parallel loading is not compatible with image compression,
so if dfs.image.compress is set to true this setting will be
ignored and no parallel loading will occur.
Enabling this feature may impact rolling upgrades and downgrades if
the previous version does not support this feature. If the feature was
enabled and a downgrade is required, first set this parameter to
false and then save the namespace to create a fsimage with no
sub-sections and then perform the downgrade.
</description></property><property><name>dfs.image.parallel.target.sections</name><value>12</value><description> Controls the number of sub-sections that will be written to
fsimage for each section. This should be larger than
dfs.image.parallel.threads, otherwise all threads will not be
used when loading. Ideally, have at least twice the number
of target sections as threads, so each thread must load more
than one section to avoid one long running section affecting
the load time.
</description></property><property><name>dfs.image.parallel.inode.threshold</name><value>1000000</value><description> If the image contains less inodes than this setting, then
do not write sub-sections and hence disable parallel loading.
This is because small images load very quickly in serial and
parallel loading is not needed.
</description></property><property><name>dfs.image.parallel.threads</name><value>12</value><description> The number of threads to use when dfs.image.parallel.load is
enabled. This setting should be less than
dfs.image.parallel.target.sections. The optimal number of
threads will depend on the hardware and environment.
</description></property>
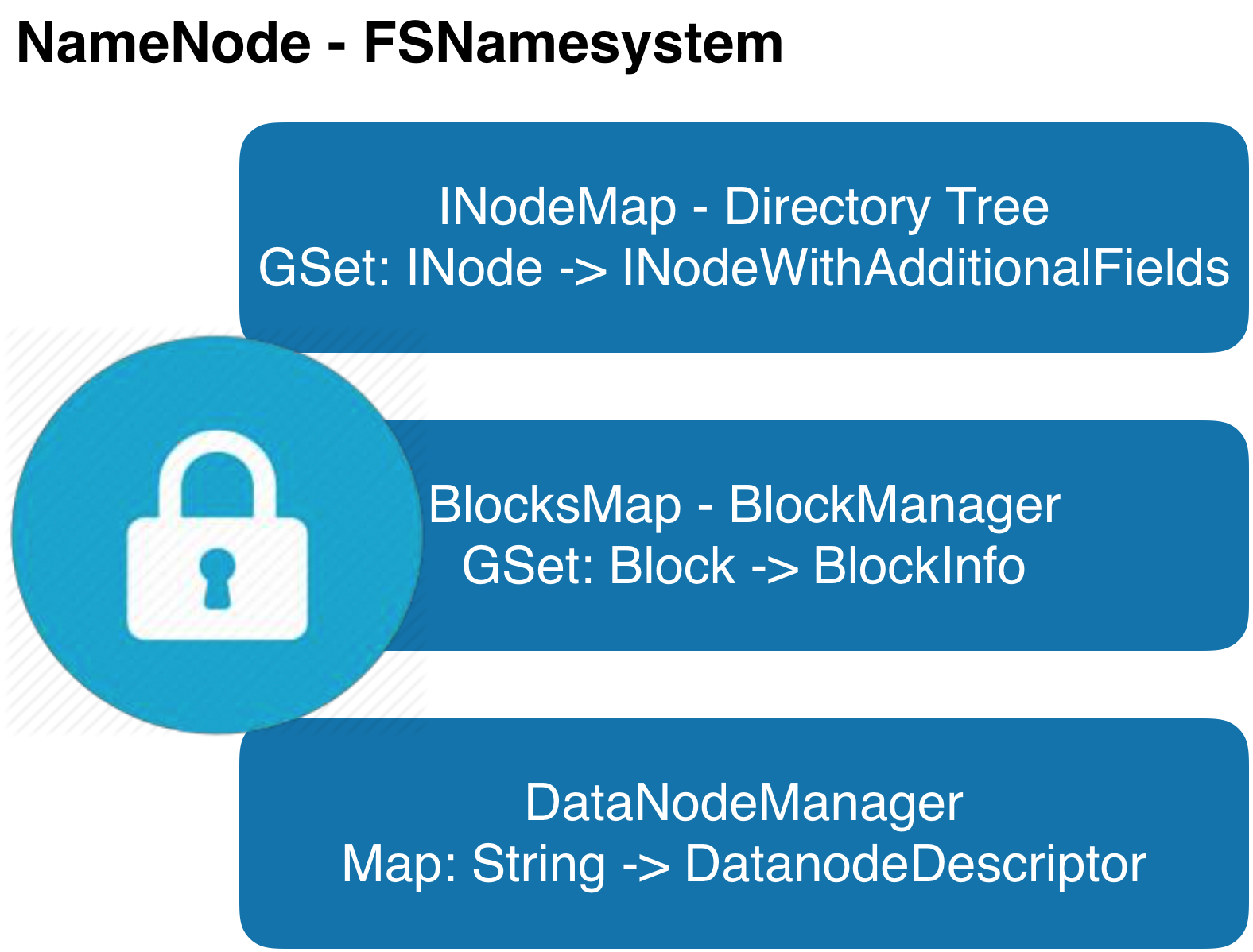
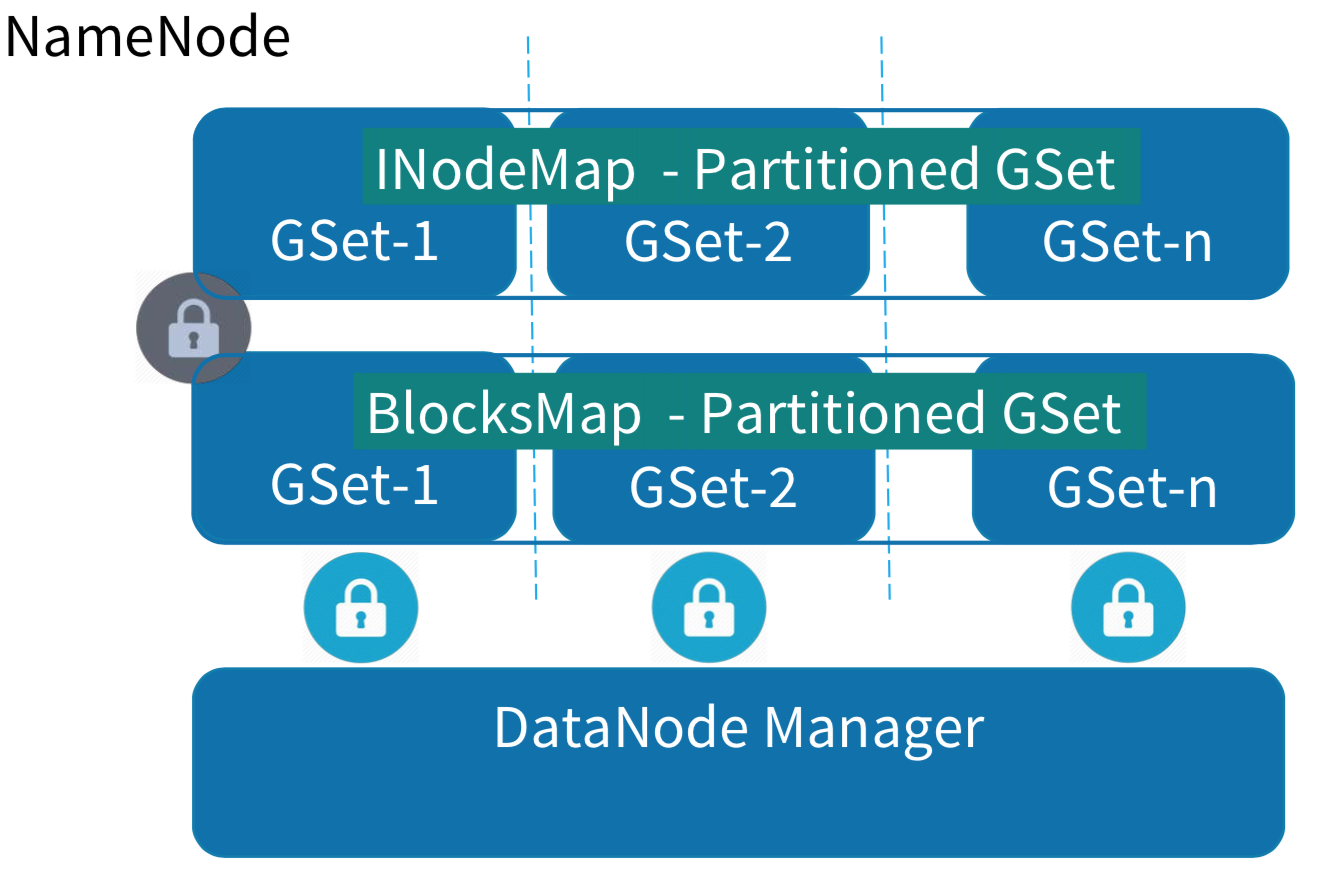
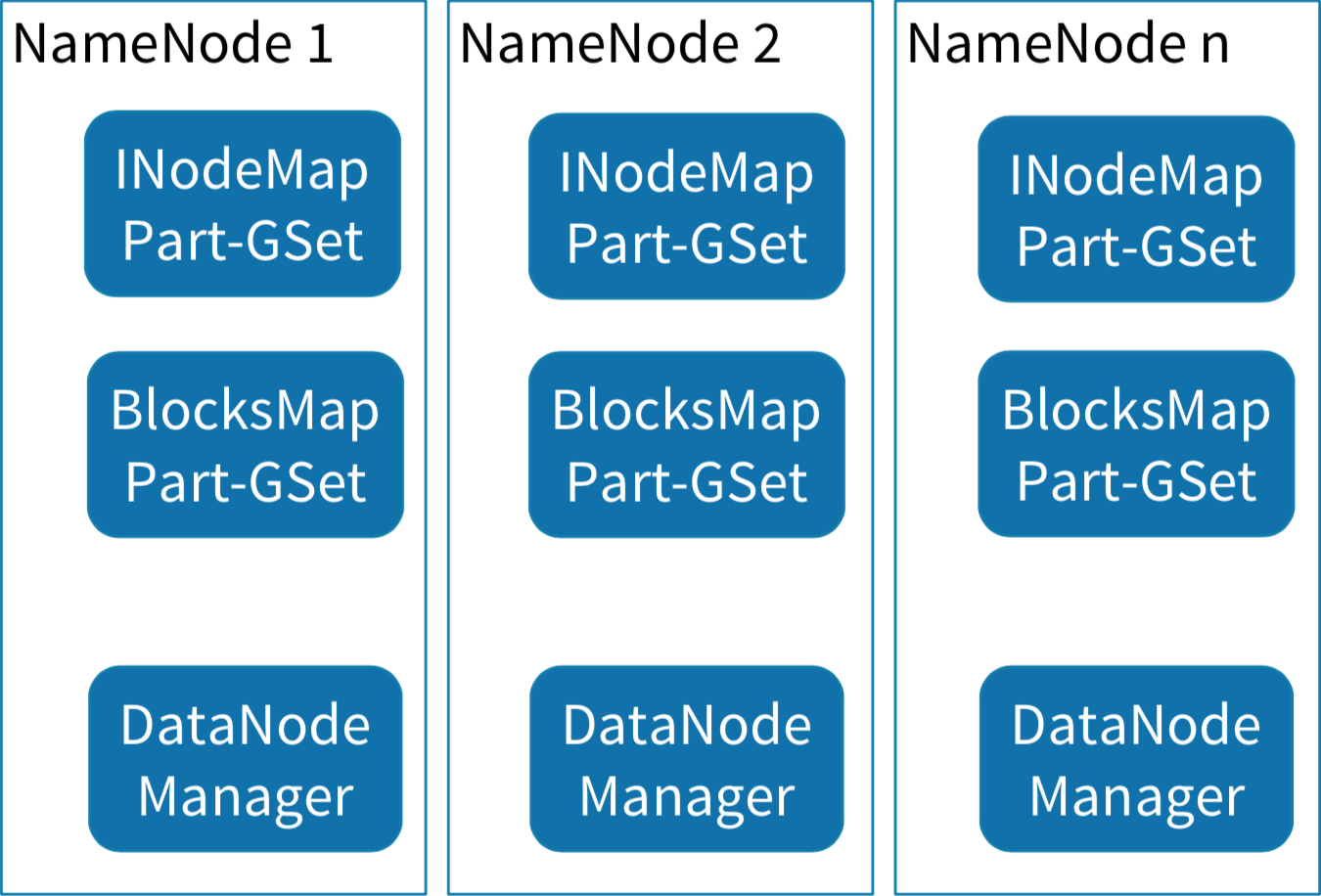
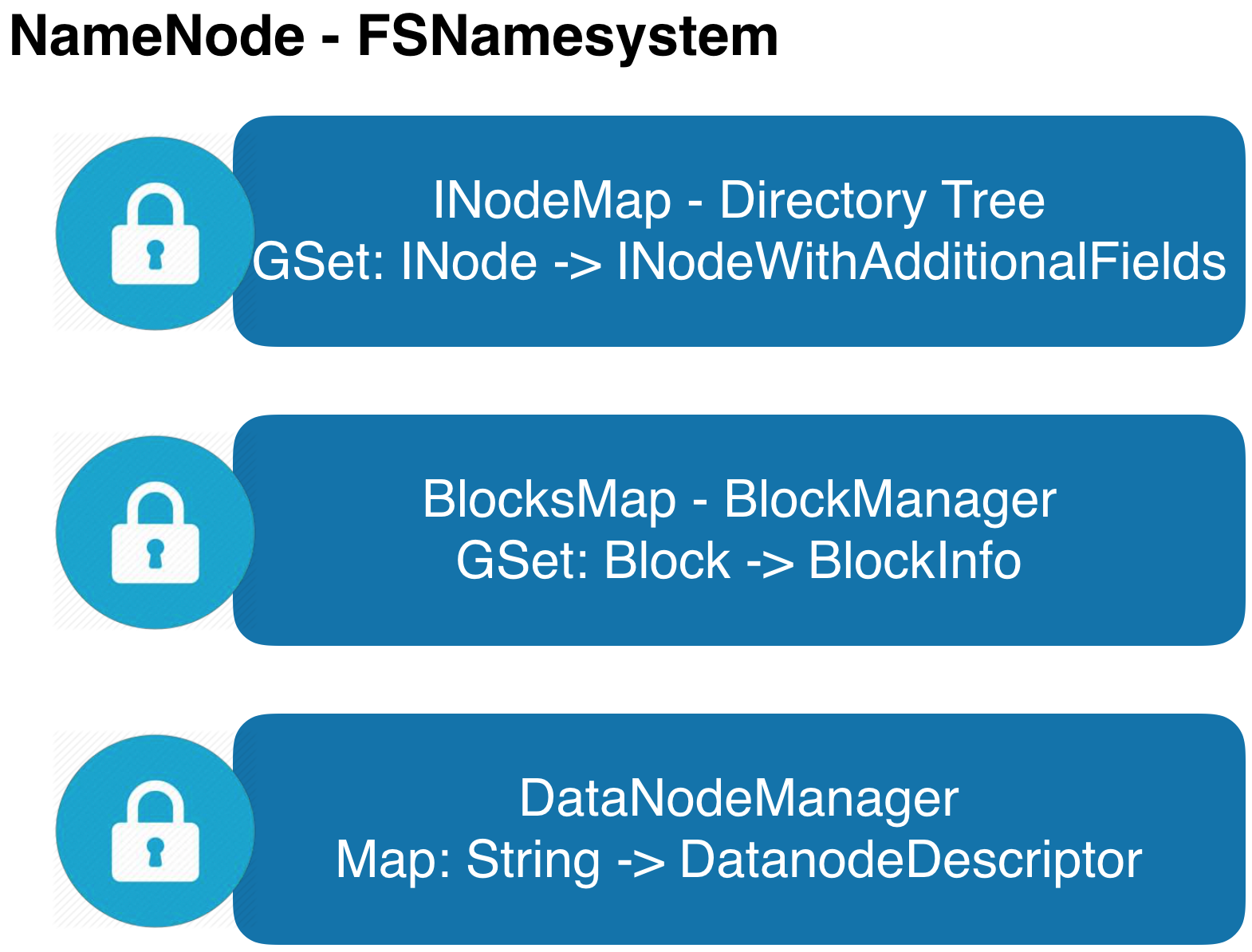
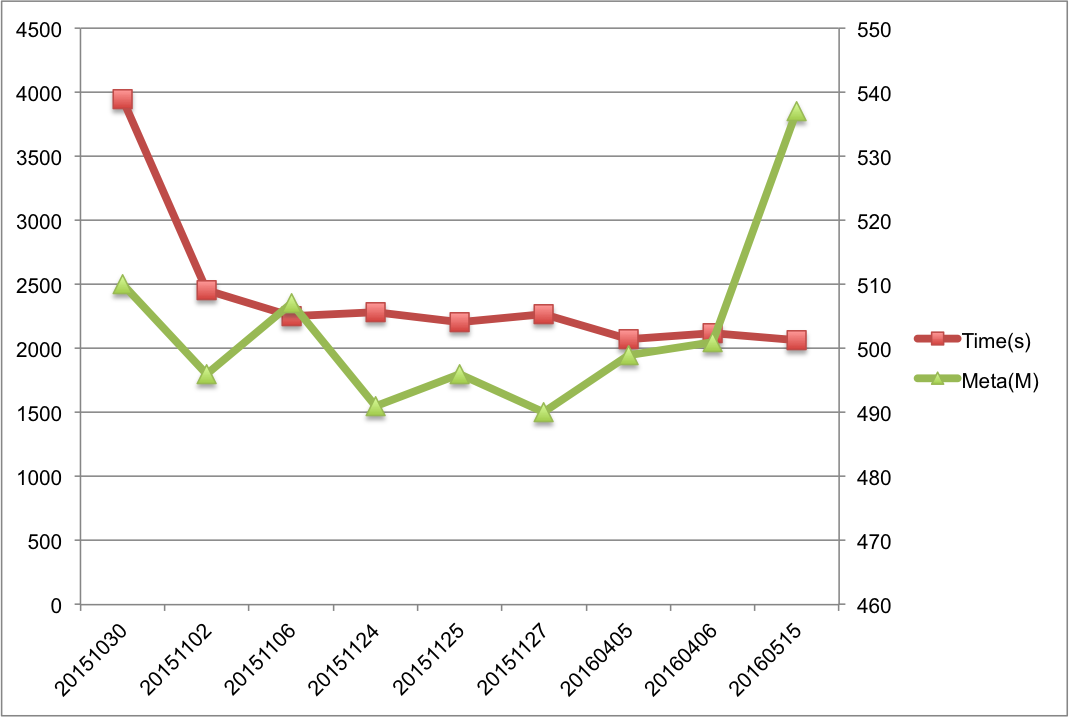
HDFS-8966:Separate the lock used in namespace and block management layer HDFS-5453:Support fine grain locking in FSNamesystem HDFS-8286:Scaling out the namespace using KV store HDFS-7836:BlockManager Scalability Improvements
重新回顾GFS1.0是如何管理目录树和目录锁。下面是从论文《The Google File System》[4]中摘抄的有关目录树和锁机制的描述段落。
Many master operations can take a long time: for example, a snapshot operation has to revoke chunkserver leases on all chunks covered by the snapshot. We do not want to delay other master operations while they are running. Therefore, we allow multiple operations to be active and use locks over regions of the namespace to ensure proper serialization. Unlike many traditional file systems, GFS does not have a per-directory data structure that lists all the files in that directory. Nor does it support aliases for the same file or directory (i.e, hard or symbolic links in Unix terms). GFS logically represents its namespace as a lookup table mapping full pathnames to metadata. With prefix compression, this table can be efficiently represented in memory. Each node in the namespace tree (either an absolute file name or an absolute directory name) has an associated read-write lock. Each master operation acquires a set of locks before it runs. Typically, if it involves /d1/d2/…/dn/leaf, it will acquire read-locks on the directory names /d1, /d1/d2, …, /d1/d2/…/dn, and either a read lock or a write lock on the full pathname /d1/d2/…/dn/leaf. Note that leaf may be a file or directory depending on the operation. We now illustrate how this locking mechanism can prevent a file /home/user/foo from being created while /home/user is being snapshotted to /save/user. The snapshot operation acquires read locks on /home and /save, and write locks on /home/user and /save/user. The file creation acquires read locks on /home and /home/user, and a write lock on /home/user/foo. The two operations will be serialized properly because they try to obtain conflicting locks on /home/user. File creation does not require a write lock on the parent directory because there is no “directory”, or inode-like, data structure to be protected from modification. The read lock on the name is sufficient to protect the parent directory from deletion. One nice property of this locking scheme is that it allows concurrent mutations in the same directory. For example, multiple file creations can be executed concurrently in the same directory: each acquires a read lock on the directory name and a write lock on the file name. The read lock on the directory name suffices to prevent the directory from being deleted, renamed, or snapshotted. The write locks on file names serialize attempts to create a file with the same name twice. Since the namespace can have many nodes, read-write lock objects are allocated lazily and deleted once they are not in use. Also, locks are acquired in a consistent total order to prevent deadlock: they are first ordered by level in the namespace tree and lexicographically within the same level.
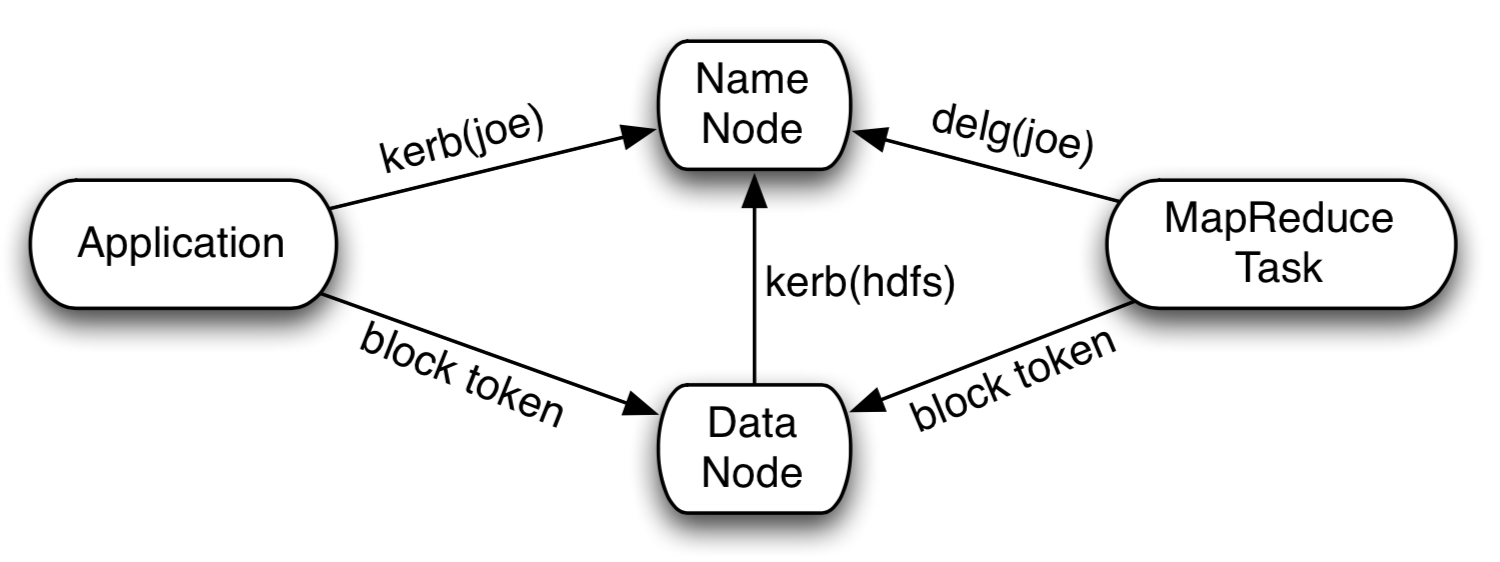
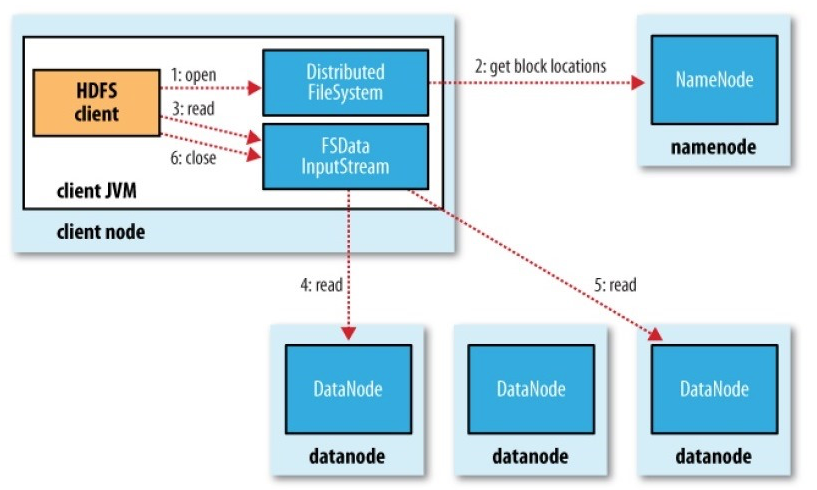
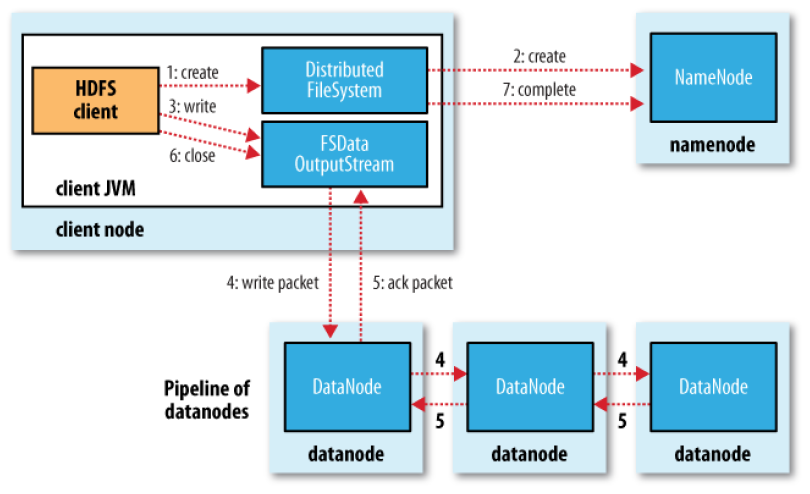
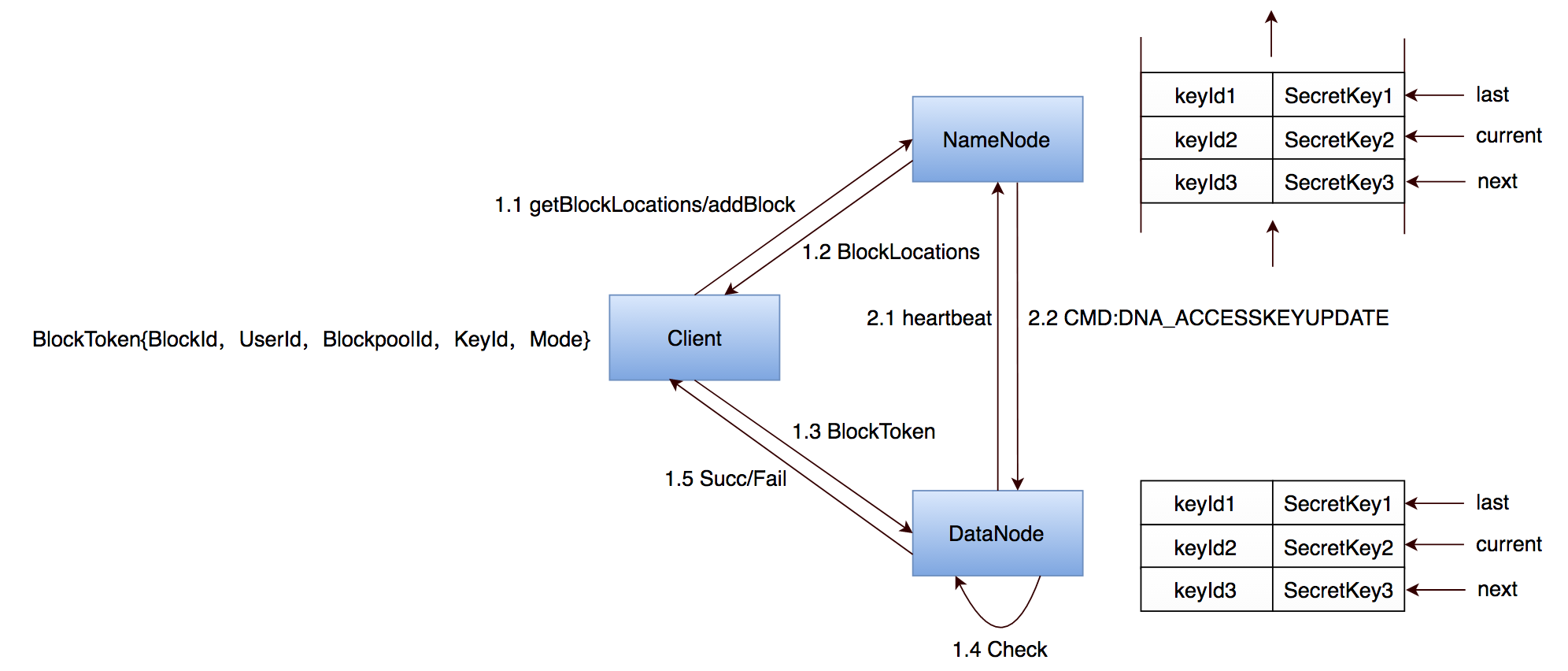
publicclassLocatedBlock{privatefinalExtendedBlockb;privatelongoffset;// offset of the first byte of the block in the fileprivatefinalDatanodeInfoWithStorage[]locs;/** Cached storage ID for each replica */privateString[]storageIDs;/** Cached storage type for each replica, if reported. */privateStorageType[]storageTypes;// corrupt flag is true if all of the replicas of a block are corrupt.// else false. If block has few corrupt replicas, they are filtered and // their locations are not part of this objectprivatebooleancorrupt;privateToken<BlockTokenIdentifier>blockToken=newToken<BlockTokenIdentifier>();......}
2017-05-17 23:41:58,952 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: hostname:50010:DataXceiver error processing WRITE_BLOCK operation src: /ip:port
dst: /ip:port
org.apache.hadoop.security.token.SecretManager$InvalidToken: Can't re-compute password for block_token_identifier (expiryDate=*, keyId=*, userId=*, blockPoolId=*, blockId=*, access modes=[WRITE]), since the required block key (keyID=*) doesn't exist.
at org.apache.hadoop.hdfs.security.token.block.BlockTokenSecretManager.retrievePassword(BlockTokenSecretManager.java:384)
at org.apache.hadoop.hdfs.security.token.block.BlockTokenSecretManager.checkAccess(BlockTokenSecretManager.java:302)
at org.apache.hadoop.hdfs.security.token.block.BlockPoolTokenSecretManager.checkAccess(BlockPoolTokenSecretManager.java:97)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.checkAccess(DataXceiver.java:1271)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.writeBlock(DataXceiver.java:663)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opWriteBlock(Receiver.java:137)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:74)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:251)
at java.lang.Thread.run(Thread.java:745)
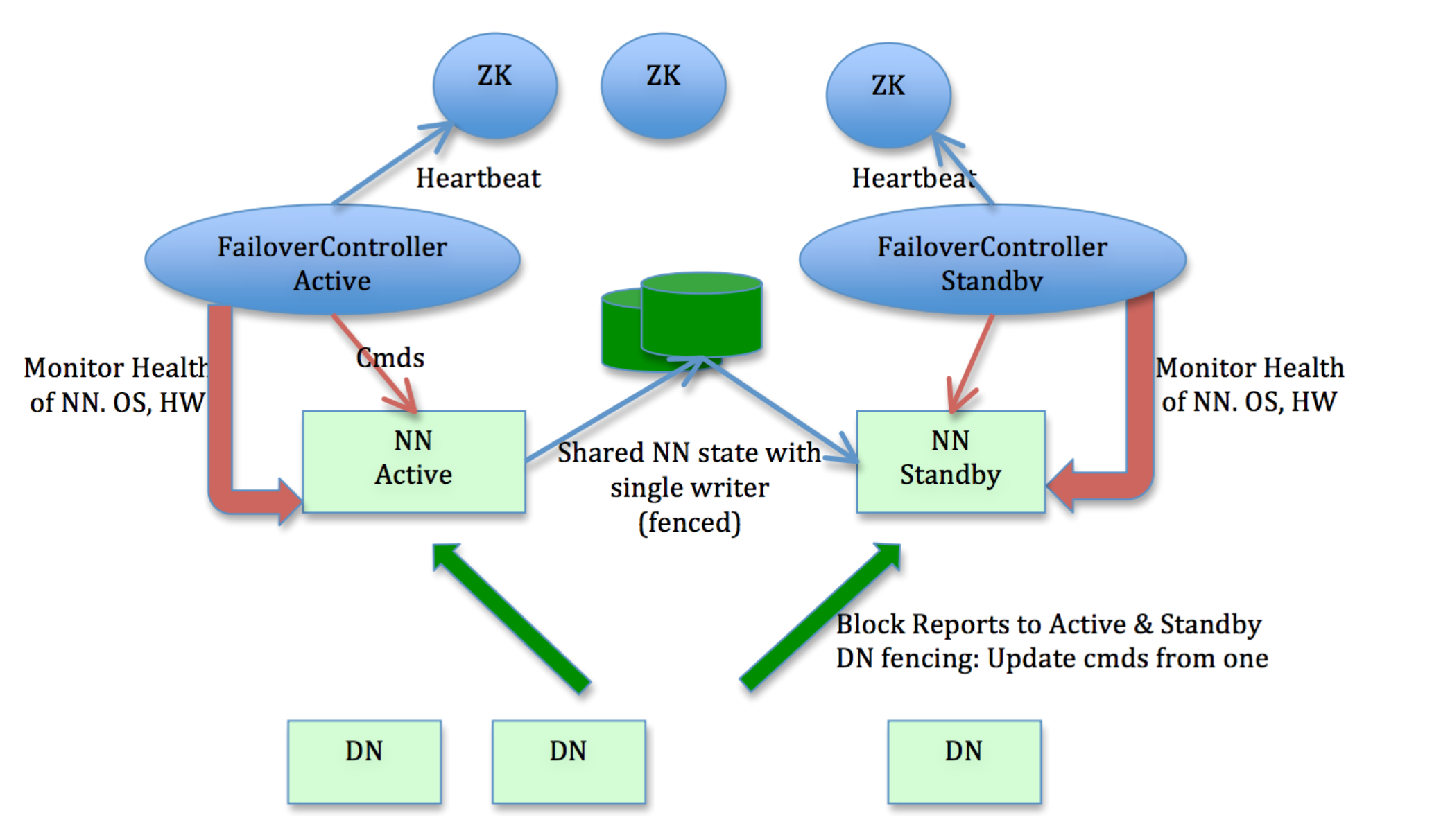
Hadoop 2.0时期,Hadoop的所有单点问题基本得到了解决。其中HDFS的高可用(High Availability,HA)在社区经过多种方案的讨论后,最终Cloudera的HA using Quorum Journal Manager(QJM)方案被社区接收,并在Hadoop 2.0版本中发布。
本文将从HDFS HA发展路径,架构原理,实现细节及使用过程中可能遇到的问题几个方面对HDFS NameNode高可用机制(主要是HDFS using QJM,不包含ZKFC)进行简单梳理和分析。
对比AvatarNode,HA using QJM方案不再存在SPOF问题,High Availability特性明显提升,同时具备了自动Failover能力。正是其良好的设计和容错能力,HDFS HA using QJM方案在2012年随Hadoop 2.0正式发布,此后一直是Hadoop社区默认HDFS HA方案。
当然除了上面提到两种典型的HDFS HA方案外,社区其实在HA特性上进行过多次尝试。
开始于2008年,并随Hadoop 0.21发布的BackupNode方案(参考:HADOOP-4539);2011年通过单独分支HDFS HA Branch开发的功能非常丰富的HDFS HA方案,并在Hadoop 0.23发布(参考:HDFS-1623),其中LinuxHA和BookKeeper方案都出自这里;等等不一而足。
三、HA using QJM原理
3.1 HA using QJM架构
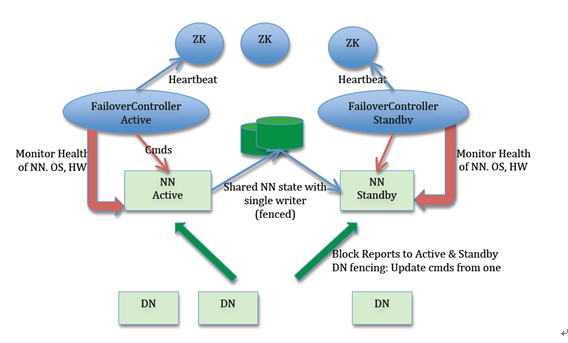
HA using Quorum Journal Manager (QJM)是当前主流HDFS HA方案,由Cloudera工程师Todd Lipcon在2012年发起,随Hadoop 2.0.3发布,此后一直被视为HDFS HA默认方案。
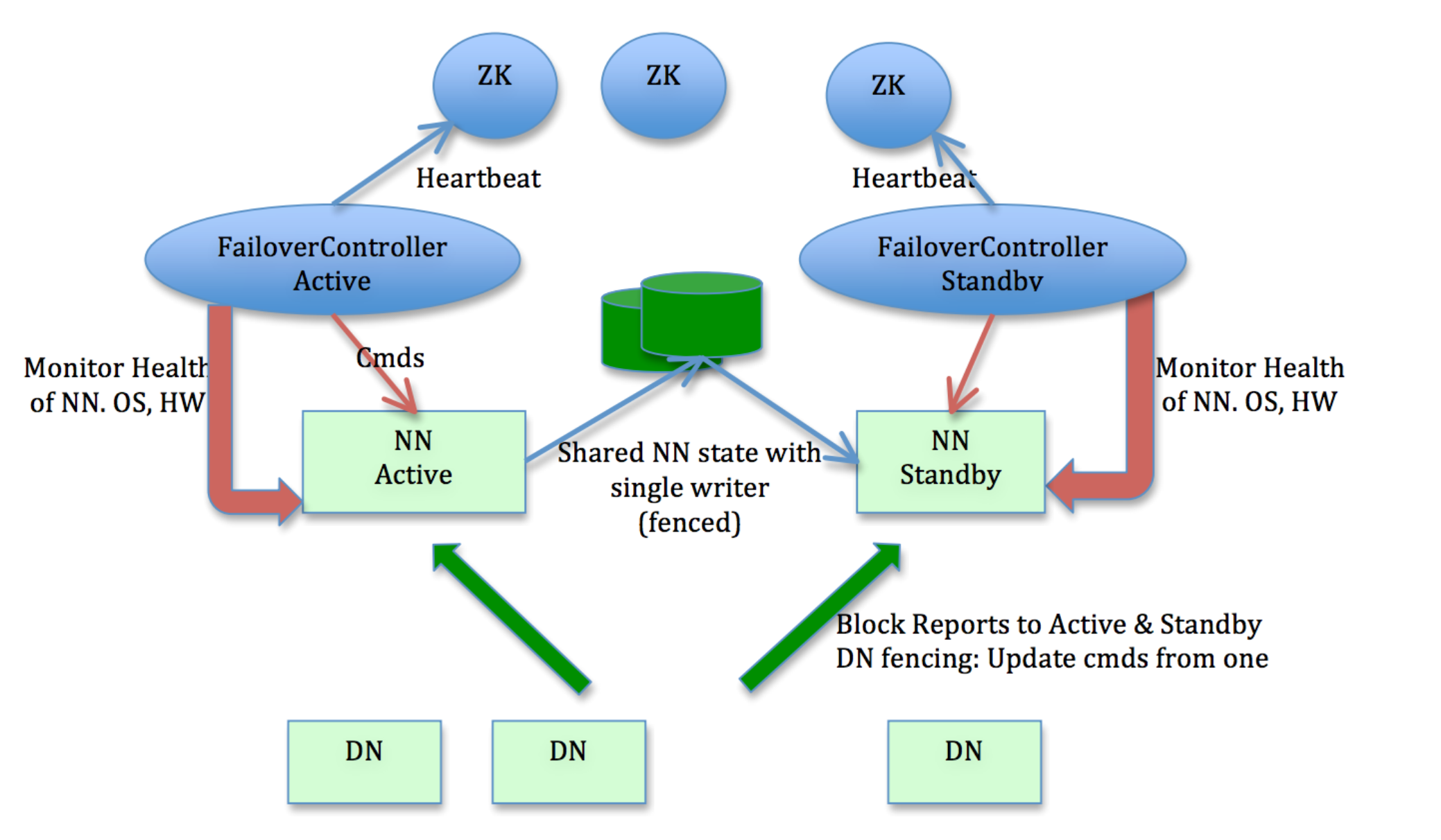
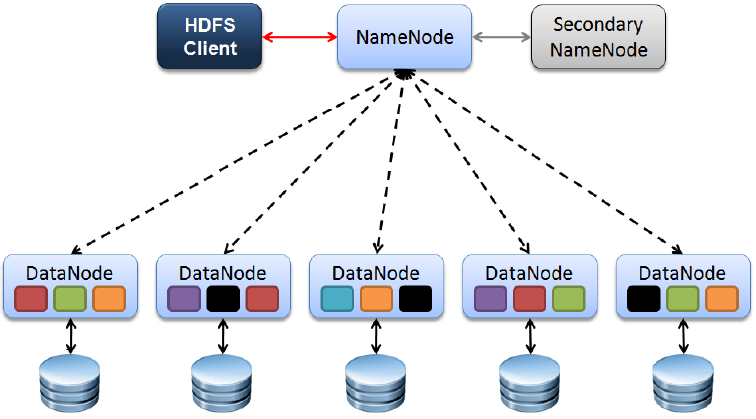
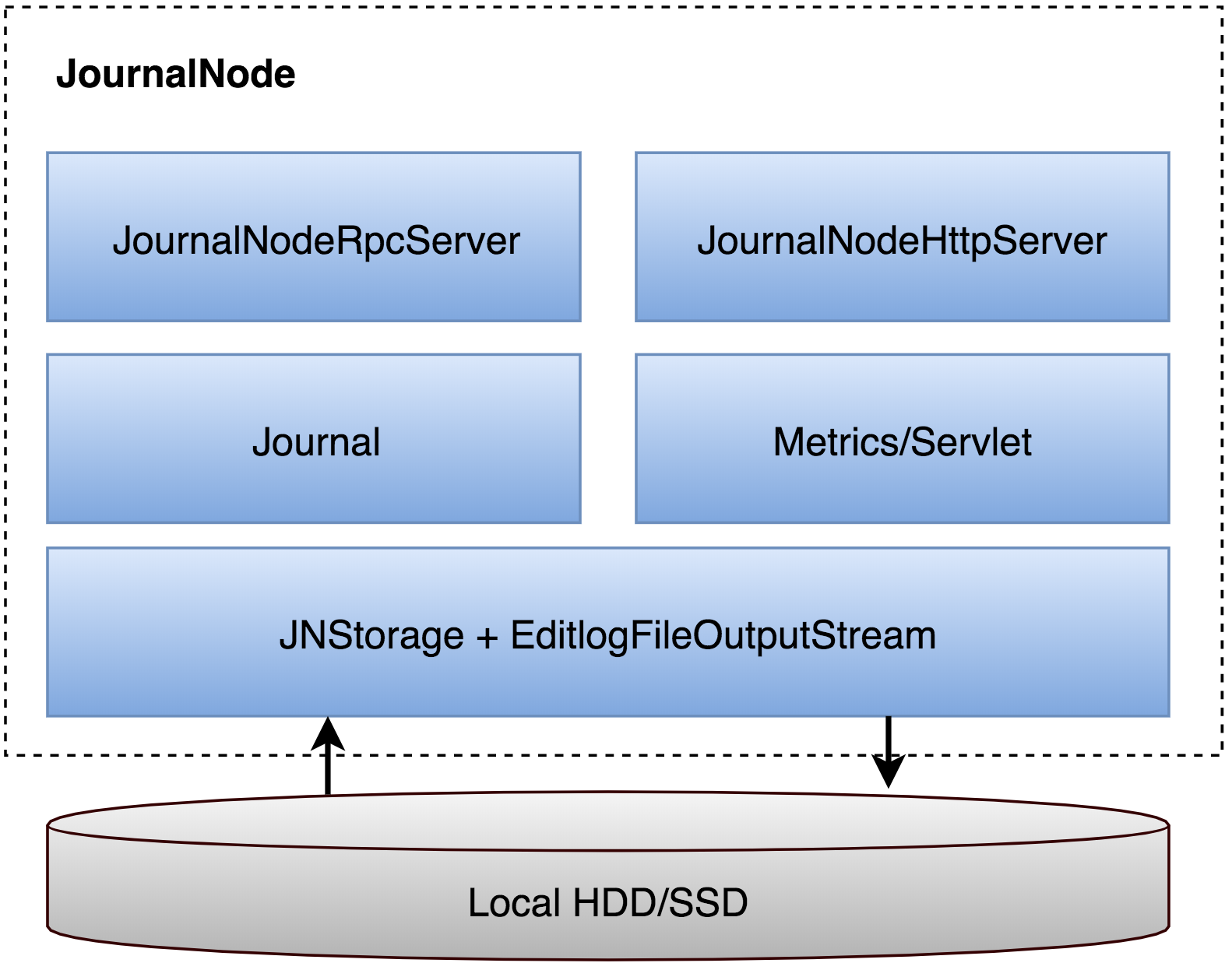
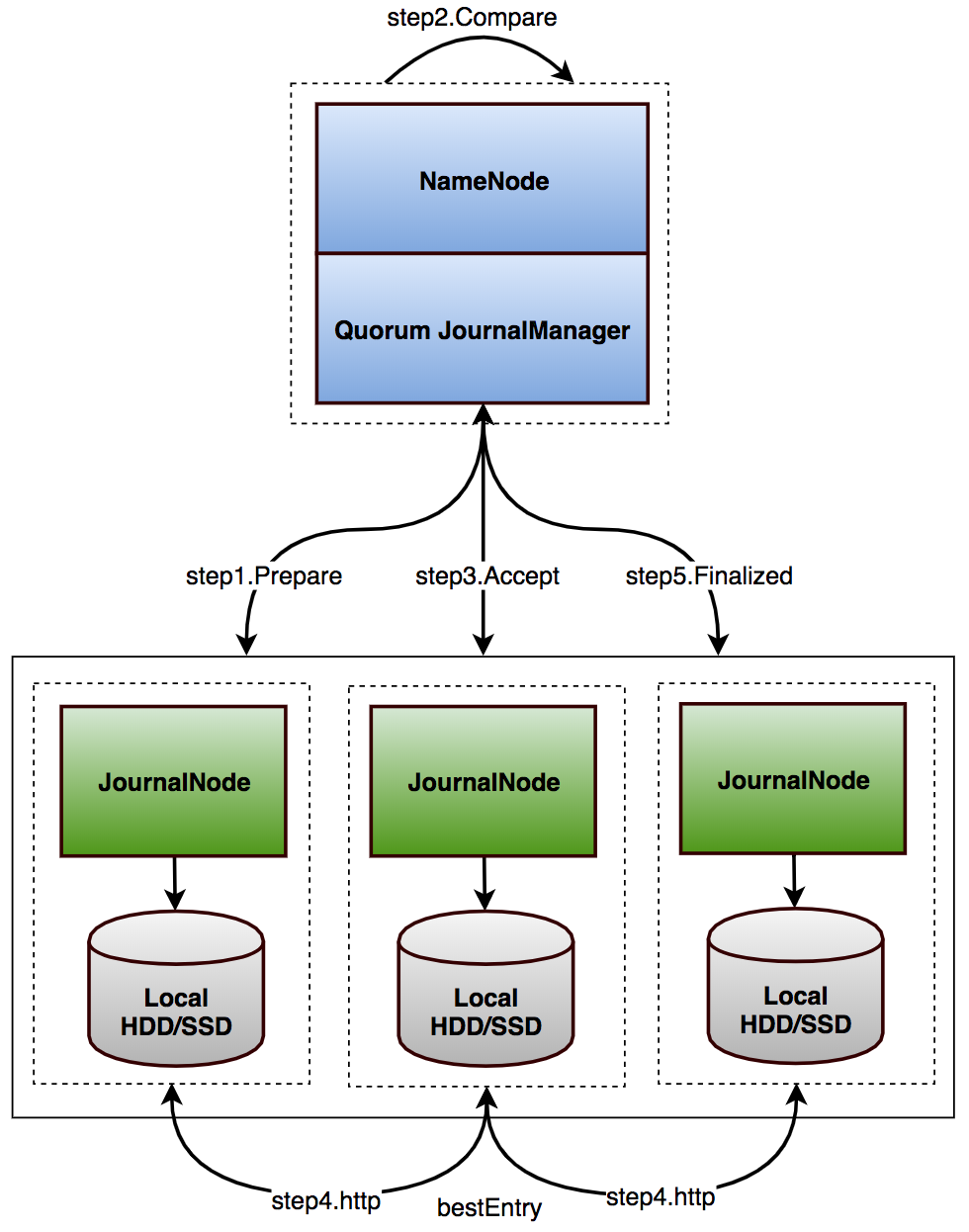
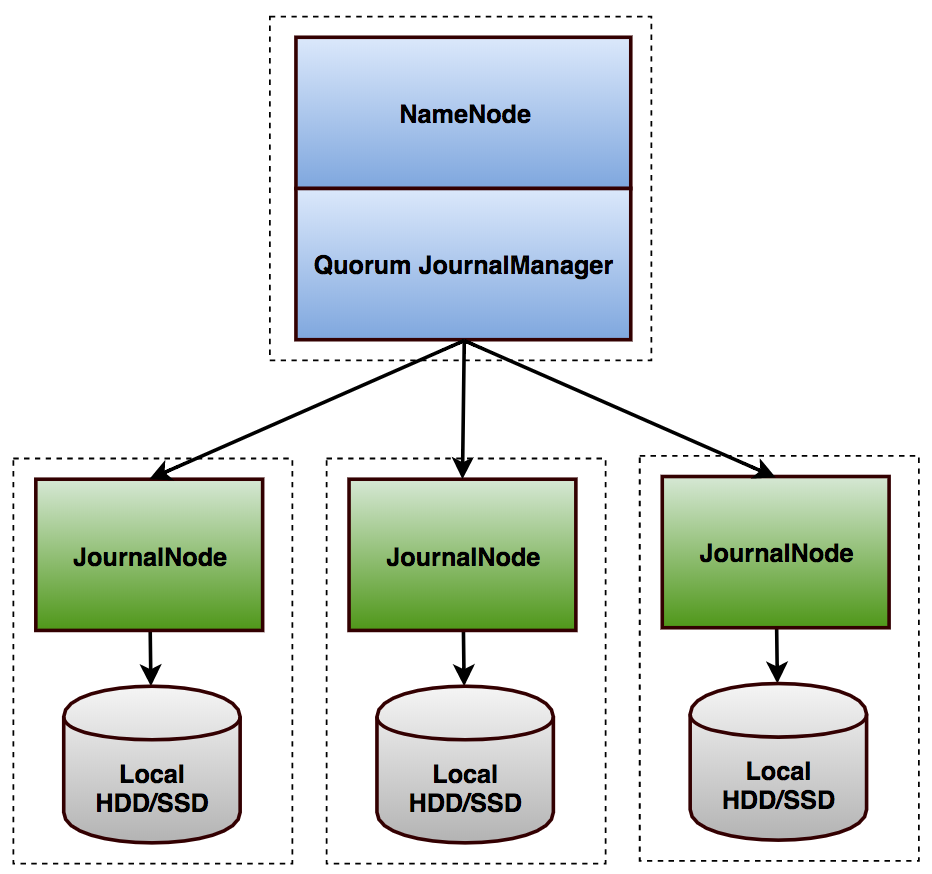
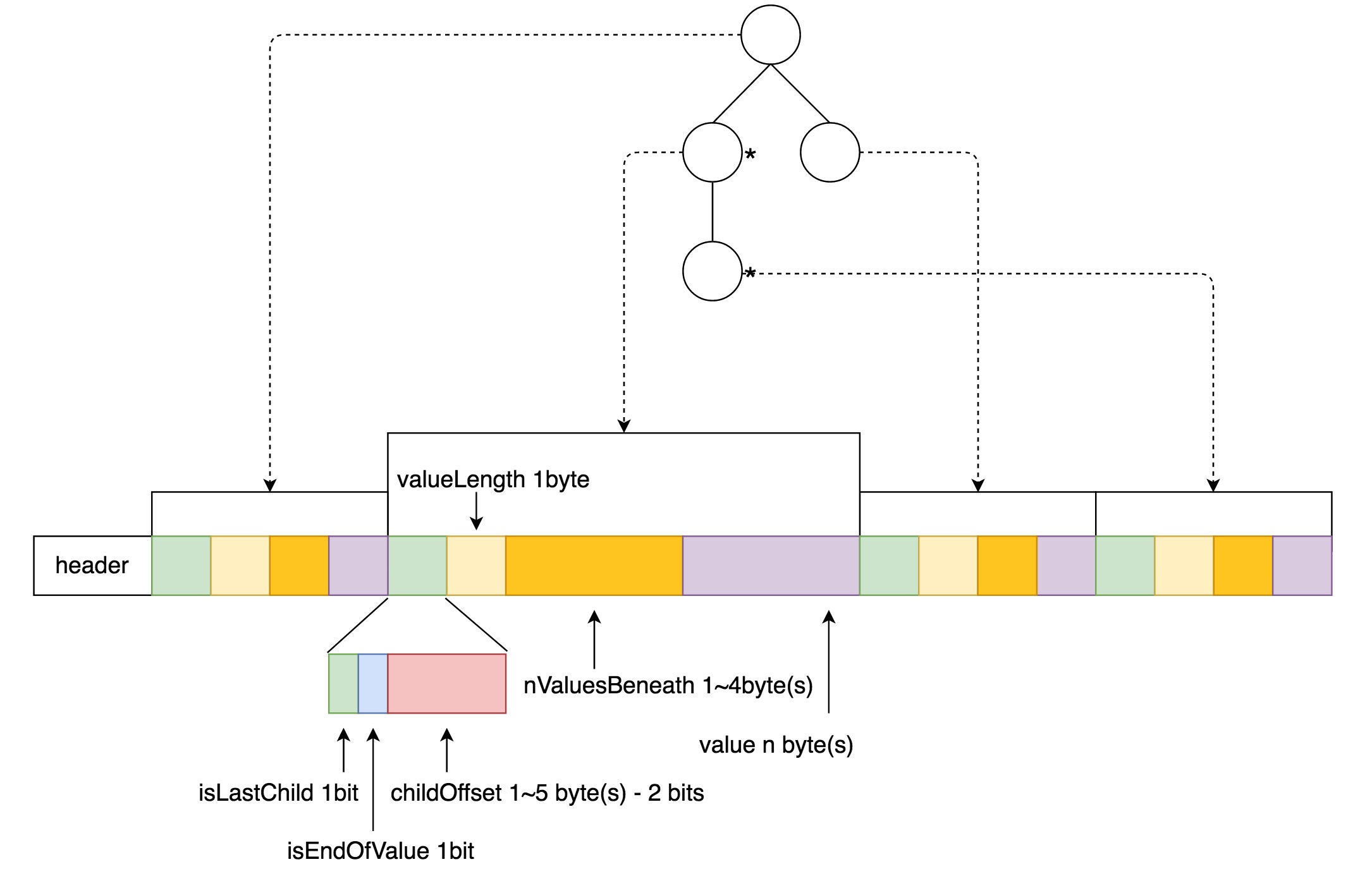
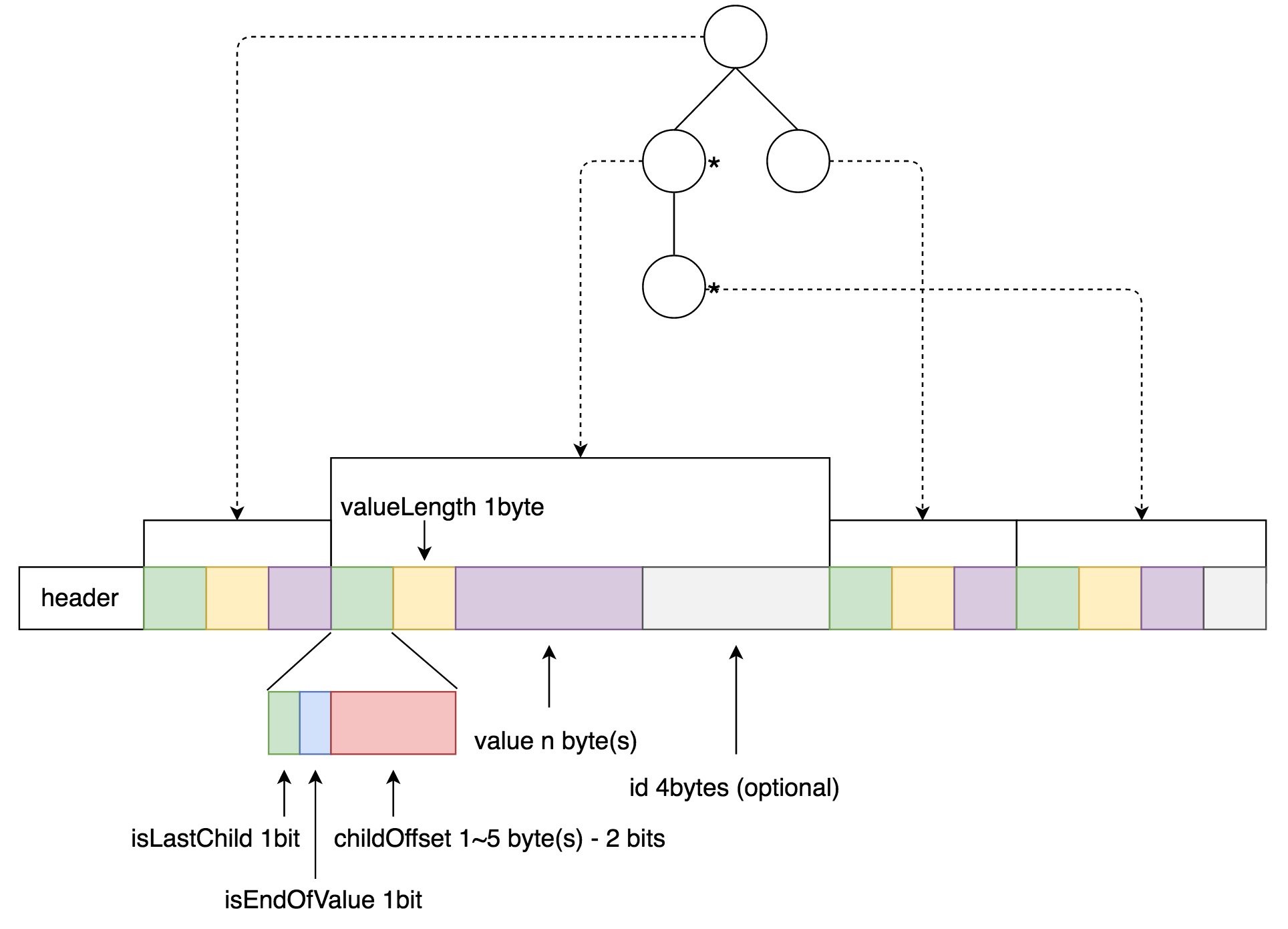
在HA using QJM方案中,涉及到的核心组件(见图3)包括:
Active NameNode(ANN):在HDFS集群中,对外提供读写服务的唯一Master节点。ANN将客户端请求过来的写操作通过EditLog写入共享存储系统(即JournalNode Cluster),为Standby NameNode及时同步数据提供支持;
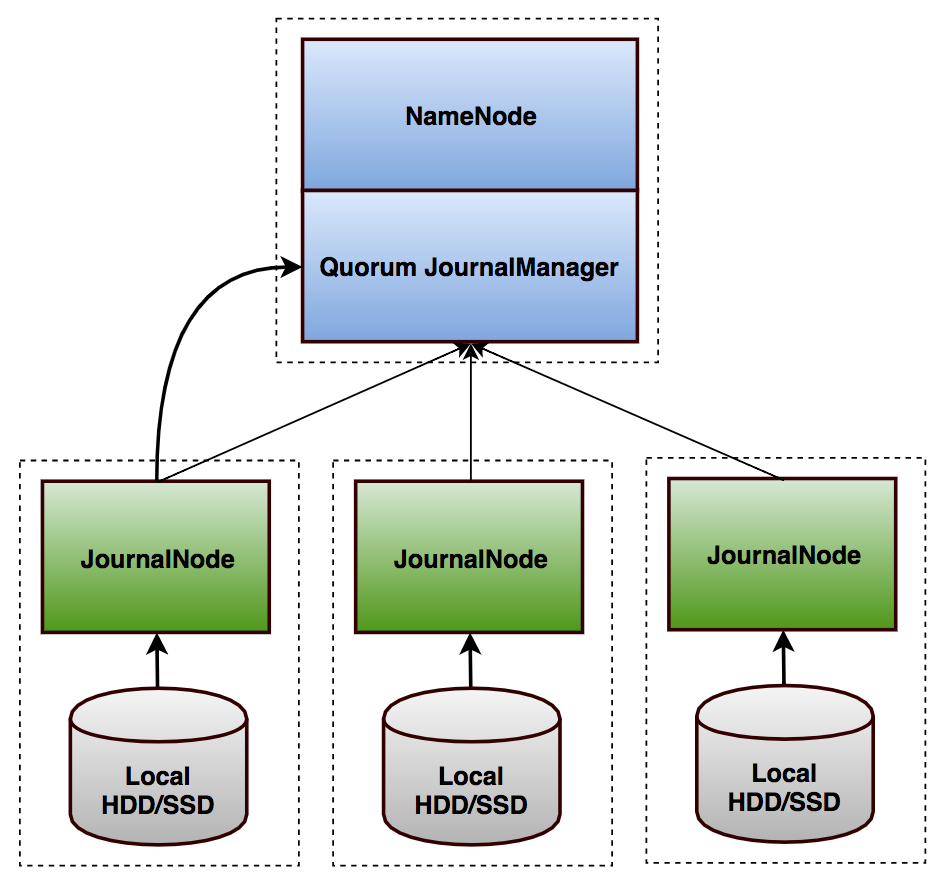
如前述,以上两步可以在QJournal防止NameNode Brain-Split。这种竞争写入的方式可以保证任意时间最多只能存在一个NameNode有能力写入JournalNode,也是QJournal强一致的基础(关于该算法强一致性模型的形式化证明可参考Paxos made Simple[2])。
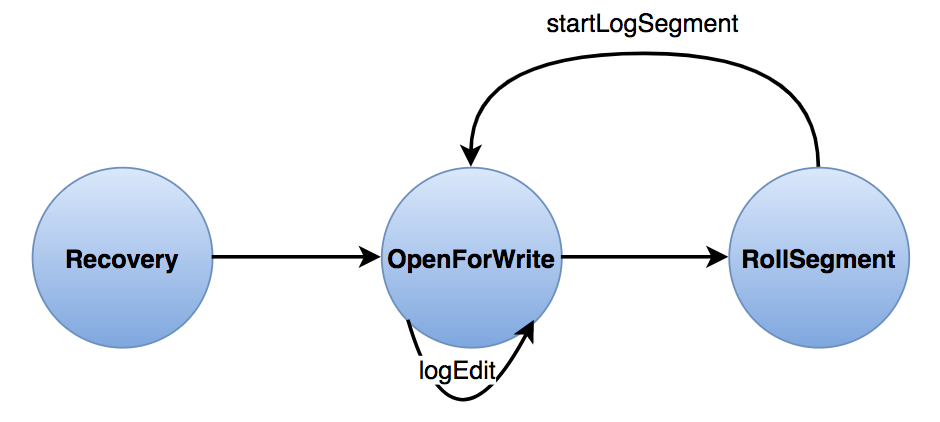
HA with QJM架构下,NameNode的整个重启过程中始终以SBN(StandbyNameNode)角色完成。与前述流程对应,启动过程分以下几个阶段:
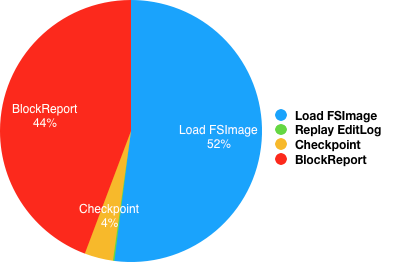
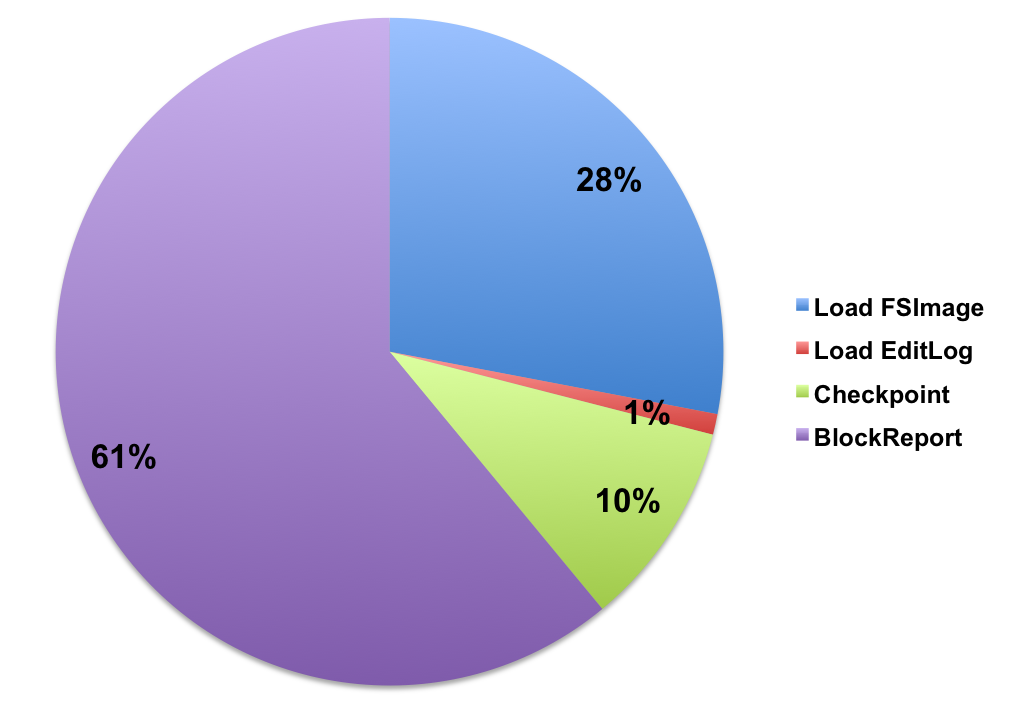
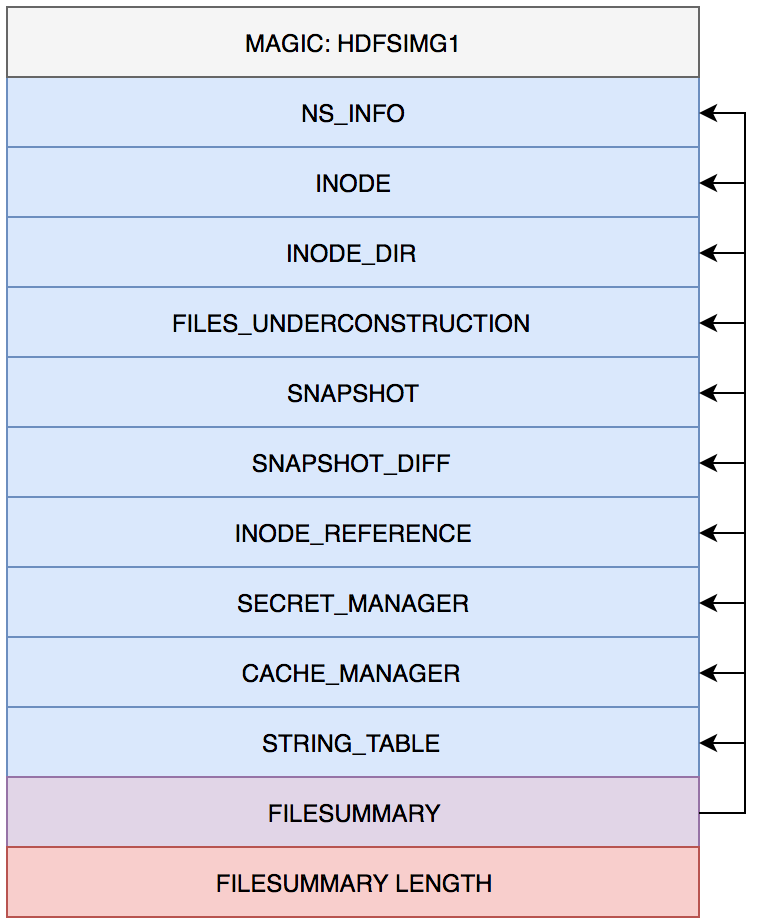
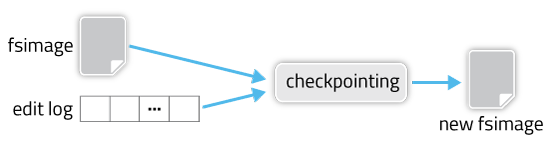
0、加载FSImage;
1、回放EditLog;
2、执行Checkpoint;(非必须步骤,结合实际情况和参数确定,后续详述)
3、收集所有DataNode的注册和数据块汇报;
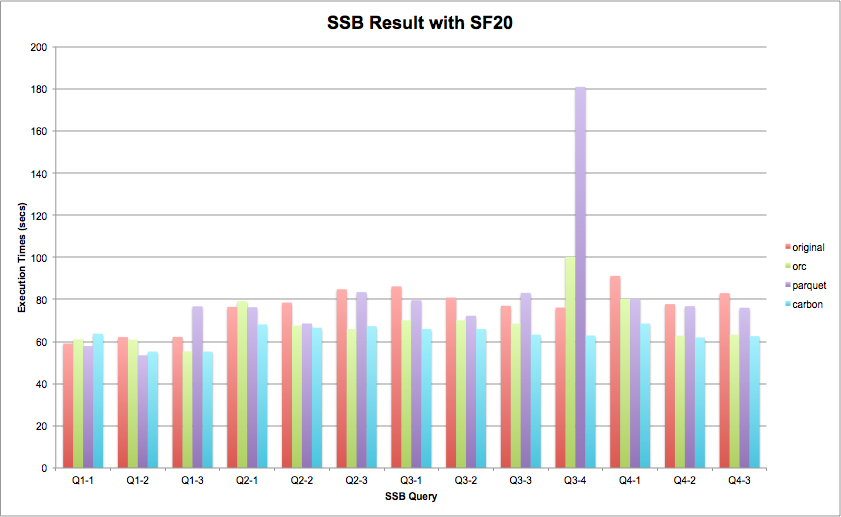
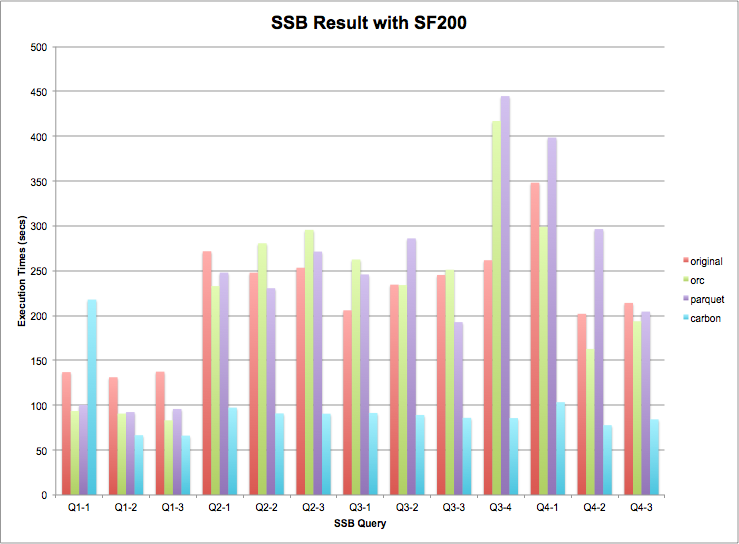
Q1.1
select sum(lo_extendedprice*lo_discount) as revenue
from lineorder, date
where lo_orderdate = d_datekey
and d_year = 1993
and lo_discount between 1 and 3
and lo_quantity < 25;FF =(1/7)*0.5*(3/11)=0.0194805#oflineorder =0.0194805*6,000,000≈116,883Q1.2selectsum(lo_extendedprice*lo_discount)asrevenuefromlineorder,datewherelo_orderdate =d_datekeyandd_yearmonthnum =199401andlo_discountbetween4and6andlo_quantitybetween26and35;FF =(1/84)*(3/11)*0.2=0.00064935#oflineorder =0.00064935*6,000,000≈3896Q1.3selectsum(lo_extendedprice*lo_discount)asrevenuefromlineorder,datewherelo_orderdate =d_datekeyandd_weeknuminyear =6andd_year =1994andlo_discountbetween5and7andlo_quantitybetween26and35;FF =(1/364)*(3/11)*0.1=0.000075#oflineorder =0.000075*6,000,000≈450Q2.1selectsum(lo_revenue),d_year,p_brand1fromlineorder,date,part,supplierwherelo_orderdate =d_datekeyandlo_partkey =p_partkeyandlo_suppkey =s_suppkeyandp_category ='MFGR#12'ands_region ='AMERICA'groupbyd_year,p_brand1orderbyd_year,p_brand1;pcategory ='MFGR#12',FF =1/25;sregion,FF=1/5.FF =(1/25)*(1/5)=1/125#oflineorder =(1/125)*6,000,000≈48,000Q2.2selectsum(lo_revenue),d_year,p_brand1fromlineorder,date,part,supplierwherelo_orderdate =d_datekeyandlo_partkey =p_partkeyandlo_suppkey =s_suppkeyandp_brand1between'MFGR#2221'and'MFGR#2228'ands_region ='ASIA'groupbyd_year,p_brand1orderbyd_year,p_brand1;FF =(1/125)*(1/5)=1/625#oflineorder =(1/625)*6,000,000≈9600Q2.3selectsum(lo_revenue),d_year,p_brand1fromlineorder,date,part,supplierwherelo_orderdate =d_datekeyandlo_partkey =p_partkeyandlo_suppkey =s_suppkeyandp_brand1 ='MFGR#2221'ands_region ='EUROPE'groupbyd_year,p_brand1orderbyd_year,p_brand1;FF =(1/1000)*(1/5)=1/5000#oflineorder =(1/5000)*6,000,000≈1200Q3.1selectc_nation,s_nation,d_year,sum(lo_revenue)asrevenuefromlineorder,customer,supplier,datewherelo_custkey =c_custkeyandlo_suppkey =s_suppkeyandlo_orderdate =d_datekeyandc_region ='ASIA'ands_region ='ASIA'andd_year>= 1992 and d_year <= 1997
group by c_nation, s_nation, d_year
order by d_year asc, revenue desc;
FF = (1/5)*(1/5)*(6/7) = 6/175
# of lineorder = (6/175)*6,000,000 ≈ 205,714
Q3.2
select c_city, s_city, d_year, sum(lo_revenue) as revenue
from lineorder, customer, supplier, date
where lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_orderdate = d_datekey
and c_nation = 'UNITED STATES'
and s_nation = 'UNITED STATES'
and d_year >= 1992 and d_year <= 1997
group by c_city, s_city, d_year
order by d_year asc, revenue desc;
FF = (1/25)*(1/25)*(6/7) = 6/4375
# of lineorder = (6/4375)*6,000,000 ≈ 8,228
Q3.3
select c_city, s_city, d_year, sum(lo_revenue) as revenue
from lineorder, customer, supplier, date
where lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_orderdate = d_datekey
and (c_city='UNITED KI1' or c_city='UNITED KI5')
and (s_city='UNITED KI1' or s_city='UNITED KI5')
and d_year >= 1992 and d_year <= 1997
group by c_city, s_city, d_year
order by d_year asc, revenue desc;
FF = (1/125)*(1/125)*(6/7) = 6/109375
# of lineorder = (6/109375)*6,000,000 ≈ 329
Q3.4 "needle-in-haystack"
select c_city, s_city, d_year, sum(lo_revenue) as revenue
from lineorder, customer, supplier, date
where lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_orderdate = d_datekey
and (c_city='UNITED KI1' or c_city='UNITED KI5')
and (s_city='UNITED KI1' or s_city='UNITED KI5')
and d_yearmonth = 'Dec1997'
group by c_city, s_city, d_year
order by d_year asc, revenue desc;
FF = (1/125)*(1/125)*(1/84) = 1/1,312,500
# of lineorder = (1/1,312,500)*6,000,000 ≈ 5
Q4.1
select d_year, c_nation, sum(lo_revenue - lo_supplycost) as profit
from lineorder, date, customer, supplier, part
where lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and lo_orderdate = d_datekey
and c_region = 'AMERICA'
and s_region = 'AMERICA'
and (p_mfgr = 'MFGR#1' or p_mfgr = 'MFGR#2')
group by d_year, c_nation
order by d_year, c_nation;
FF = (1/5)(1/5)*(2/5) = 2/125
# of lineorder = (2/125)*6,000,000 ≈ 96000
Q4.2 "Drill Down to Category in 2 Specific Years"
select d_year, s_nation, p_category, sum(lo_revenue - lo_supplycost) as profit
from lineorder, date, customer, supplier, part
where lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and lo_orderdate = d_datekey
and c_region = 'AMERICA'
and s_region = 'AMERICA'
and (d_year = 1997 or d_year = 1998)
and (p_mfgr = 'MFGR#1' or p_mfgr = 'MFGR#2')
group by d_year, s_nation, p_category
order by d_year, s_nation, p_category;
FF = (2/7)*(2/125) = 4/875
# of lineorder = (4/875)*6,000,000 ≈ 27,428
Q4.3 "Further Drill Down to cities in US"
select d_year, s_city, p_brand1, sum(lo_revenue - lo_supplycost) as profit
from lineorder, date, customer, supplier, part
where lo_custkey = c_custkey and lo_suppkey = s_suppkey and lo_partkey = p_partkey and lo_orderdate = d_datekey
and c_region = 'AMERICA'
and s_nation = 'UNITED STATES'
and (d_year = 1997 or d_year = 1998)
and p_category = 'MFGR#14'
group by d_year, s_city, p_brand1
order by d_year, s_city, p_brand1;
FF = (1/5)*(1/25)*(2/7)*(1/25) = 2/21875
# of lineorder = (2/21875)*6,000,000 ≈ 549
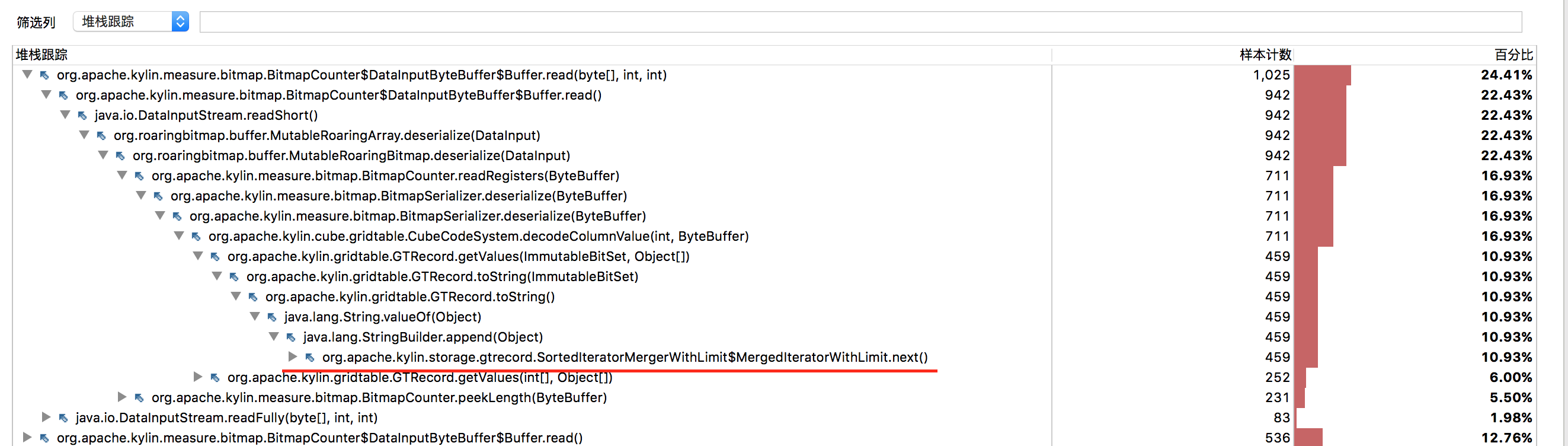
"org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$ReplicationMonitor@254e0df1" daemon prio=10 tid=0x00007f59b4364800 nid=0xa7d9 runnable [0x00007f2baf40b000]
java.lang.Thread.State: RUNNABLE
at java.util.AbstractCollection.toArray(AbstractCollection.java:195)
at java.lang.String.split(String.java:2311)
at org.apache.hadoop.net.NetworkTopology$InnerNode.getLoc(NetworkTopology.java:282)
at org.apache.hadoop.net.NetworkTopology$InnerNode.getLoc(NetworkTopology.java:292)
at org.apache.hadoop.net.NetworkTopology$InnerNode.access$000(NetworkTopology.java:82)
at org.apache.hadoop.net.NetworkTopology.getNode(NetworkTopology.java:539)
at org.apache.hadoop.net.NetworkTopology.countNumOfAvailableNodes(NetworkTopology.java:775)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseRandom(BlockPlacementPolicyDefault.java:707)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:383)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:432)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:225)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:120)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$ReplicationWork.chooseTargets(BlockManager.java:3783)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$ReplicationWork.access$200(BlockManager.java:3748)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.computeReplicationWorkForBlocks(BlockManager.java:1408)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.computeReplicationWork(BlockManager.java:1314)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.computeDatanodeWork(BlockManager.java:3719)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$ReplicationMonitor.run(BlockManager.java:3671)
at java.lang.Thread.run(Thread.java:745)
/** Given a node's string representation, return a reference to the node * @param loc string location of the form /rack/node * @return null if the node is not found or the childnode is there but * not an instance of {@link InnerNode} */privateNodegetLoc(Stringloc){if(loc==null||loc.length()==0)returnthis;String[]path=loc.split(PATH_SEPARATOR_STR,2);Nodechildnode=null;for(inti=0;i<children.size();i++){if(children.get(i).getName().equals(path[0])){childnode=children.get(i);}}if(childnode==null)returnnull;// non-existing nodeif(path.length==1)returnchildnode;if(childnodeinstanceofInnerNode){return((InnerNode)childnode).getLoc(path[1]);}else{returnnull;}}
2016-04-19 20:08:52,328 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 7 to reach 10 (unavailableStorages=[], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy
2016-04-19 20:08:52,328 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 7 to reach 10 (unavailableStorages=[DISK], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy
2016-04-19 20:08:52,328 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 7 to reach 10 (unavailableStorages=[DISK, ARCHIVE], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) All required storage types are unavailable: unavailableStorages=[DISK, ARCHIVE], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
2016-04-19 20:08:52,328 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: block = blk_8206926206_7139007477
2016-04-19 20:08:52,328 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: priority = 2
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: srcNode = 10.16.*.*:*
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: storagepolicyid = 0
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: targets is empty
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: exclude = 10.16.*.*:*
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: exclude = 10.16.*.*:*
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: exclude = 10.16.*.*:*
2016-04-19 20:08:52,329 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: ReplicationMonitor: exclude = 10.16.*.*:**
<property><name>dfs.namenode.replication.work.multiplier.per.iteration</name><value>5</value></property><property><name>dfs.namenode.replication.max-streams</name><value>50</value><description> The maximum number of outgoing replication streams a given node should have
at one time considering all but the highest priority replications needed.
</description></property><property><name>dfs.namenode.replication.max-streams-hard-limit</name><value>100</value><description> The maximum number of outgoing replication streams a given node should have
at one time.
</description></property>
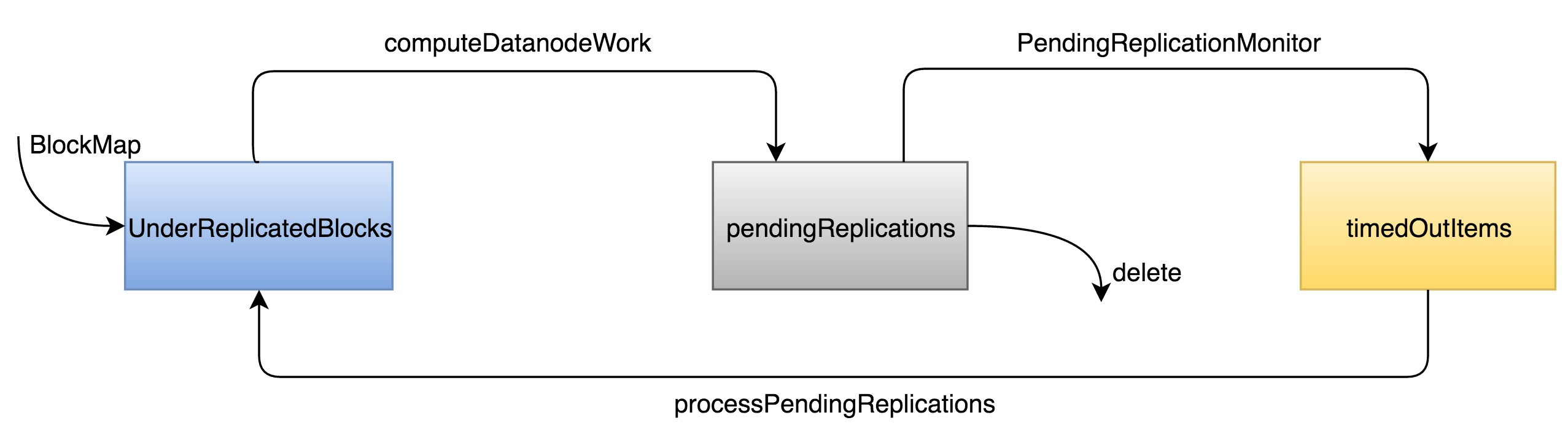
privateclassReplicationMonitorimplementsRunnable{@Overridepublicvoidrun(){while(namesystem.isRunning()){try{// Process replication work only when active NN is out of safe mode.if(namesystem.isPopulatingReplQueues()){computeDatanodeWork();processPendingReplications();rescanPostponedMisreplicatedBlocks();}Thread.sleep(replicationRecheckInterval);}catch(Throwablet){......}}}}
publicvoidremoveBlock(Blockblock){assertnamesystem.hasWriteLock();// No need to ACK blocks that are being removed entirely// from the namespace, since the removal of the associated// file already removes them from the block map below.block.setNumBytes(BlockCommand.NO_ACK);addToInvalidates(block);removeBlockFromMap(block);// Remove the block from pendingReplications and neededReplicationspendingReplications.remove(block);neededReplications.remove(block,UnderReplicatedBlocks.LEVEL);if(postponedMisreplicatedBlocks.remove(block)){postponedMisreplicatedBlocksCount.decrementAndGet();}}
......}finally{namesystem.writeUnlock();}finalSet<Node>excludedNodes=newHashSet<Node>();for(ReplicationWorkrw:work){// Exclude all of the containing nodes from being targets.// This list includes decommissioning or corrupt nodes.excludedNodes.clear();for(DatanodeDescriptordn:rw.containingNodes){excludedNodes.add(dn);}// choose replication targets: NOT HOLDING THE GLOBAL LOCK// It is costly to extract the filename for which chooseTargets is called,// so for now we pass in the block collection itself.rw.chooseTargets(blockplacement,storagePolicySuite,excludedNodes);}namesystem.writeLock();